
Objective:
The organization requires a reliable data replication solution to achieve a unified and real-time view of data from three distinct SAP source systems. By leveraging the capabilities of SAP SLT replication, data from the source systems, referred to as ECC EHP7, S/4 HANA 2020, and S/4 HANA 2021, can be seamlessly replicated to a single target system, referred to as HANA Enterprise Platform. Further, this integration enables the organization to have a consolidated and up-to-date dataset for analysis and reporting.
Key Aspects:
This consolidation enhances decision-making processes, optimizes operations, and empowers the organization to leverage data-driven insights for strategic growth and competitiveness-
- Unified Data Access
- Real-Time Replication
- Source System Tracking
- Custom Column Replication
Technical Analysis:
This includes examining the structure and data models of HANA2020, ECC, and HANA2021 to understand their variations and unique fields. For example, purposes, let us focus on tables SPFLI, SFLIGHT.
However, as per the business case, table SPFLI has one/multiple additional columns in the source system HANA2020 and HANA2021.
Source system HANA2021 has field ZYSPFLISY21COL1–
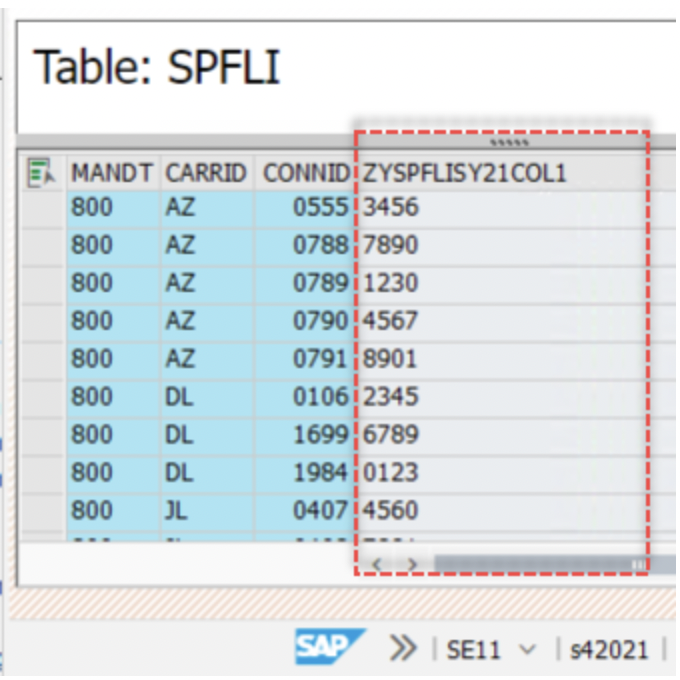
Similarly, the source system HANA2020 has field ZYSPFLISY21COL1–
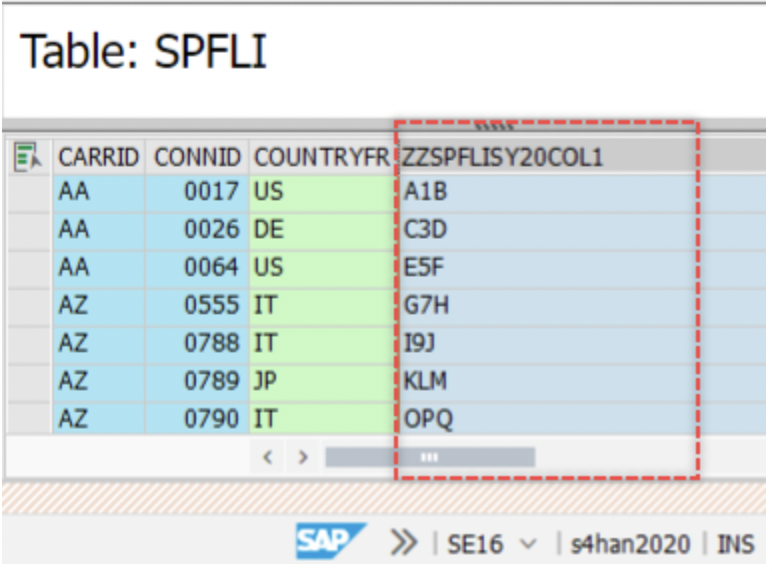
Additionally, ECC has existing fields only.
Architecture: The SLT replication architecture consists of three main components:
- Source systems,
- SLT server( could be a standalone system or a DMIS component ),
- Target system
In this demo, we have three source systems: ECC, S42020, connected to the SLT server S42021 via RFC. The S42021 also acts as another source system and the SLT server.
The target system is an on-premise HANA Enterprise Platform( HANA 2.0 SPS06 ) connected to the SLT system via a database connection.
The diagram below describes the target system table’s fields as follows:
- 1: SLT provides a column to track the source system, i.e., ZZSYSOURCE. It will be part of the target table primary key.
- A-C: Existing primary key, standard columns in source systems.
- D-I: Columns are available in one source table but not in another. SLT shall replicate these columns along with the values. Keep it blank for the sources not having data for a particular source system.
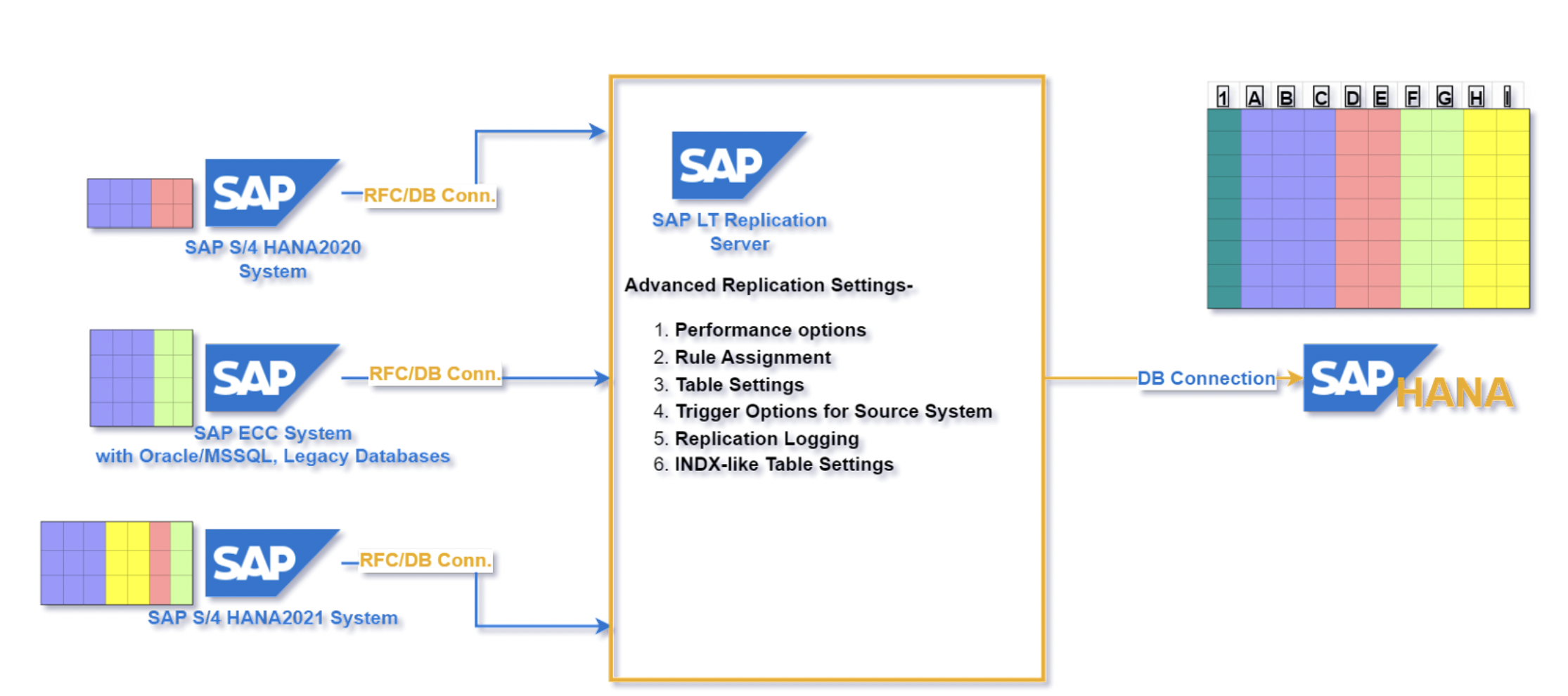
In the SLT server, we will work with LTRC and LTRS, SM59, and DBCO transaction codes. To keep it simple, we will focus on 2 points of advanced replication setting( access via LTRC )-
- Rule Assignment
- Table Settings
Also, we are going to use S/4 HANA2021 as an SLT server.
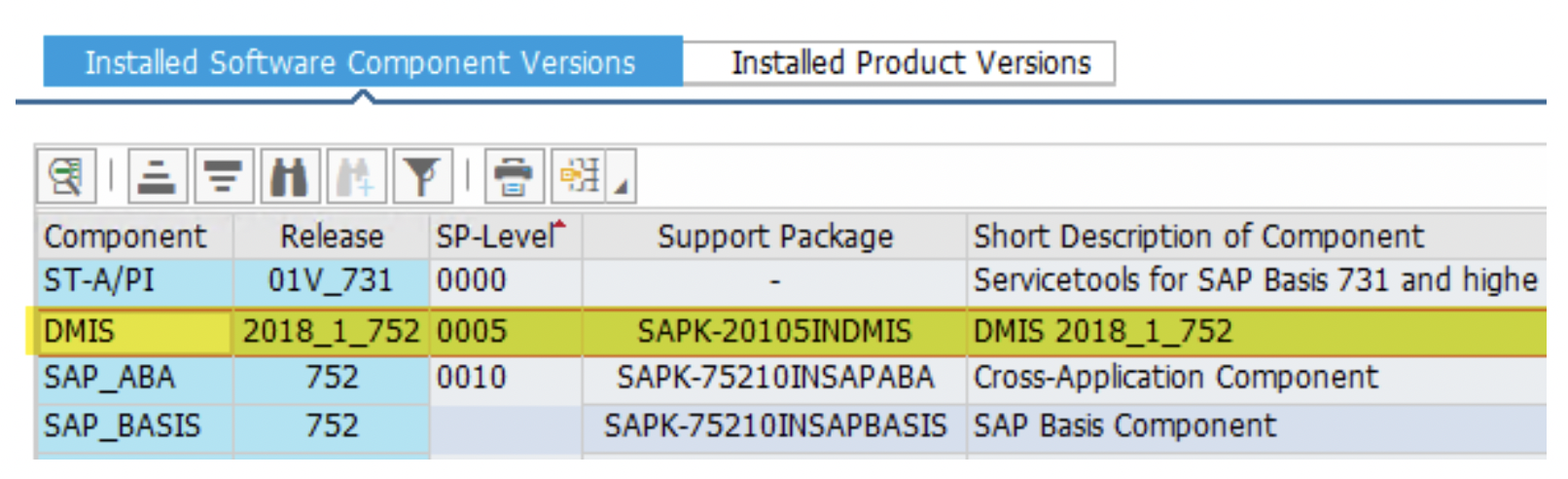
Note: A standalone SLT server is just another ECC/HANA instance having an additional component of DMIS i.e.
Technical Solution:
Source System Configuration:
To configure the source systems for SLT replication, we must establish an RFC connection between the source system and the SLT server. In this implementation, we have three source systems: ECC, S4HAN2020, and S42021, and we configure each system separately.
Carry out the activities below in the SLT server-
- S42021( SLT server ) to ECC system RFC connection using transaction SM59.
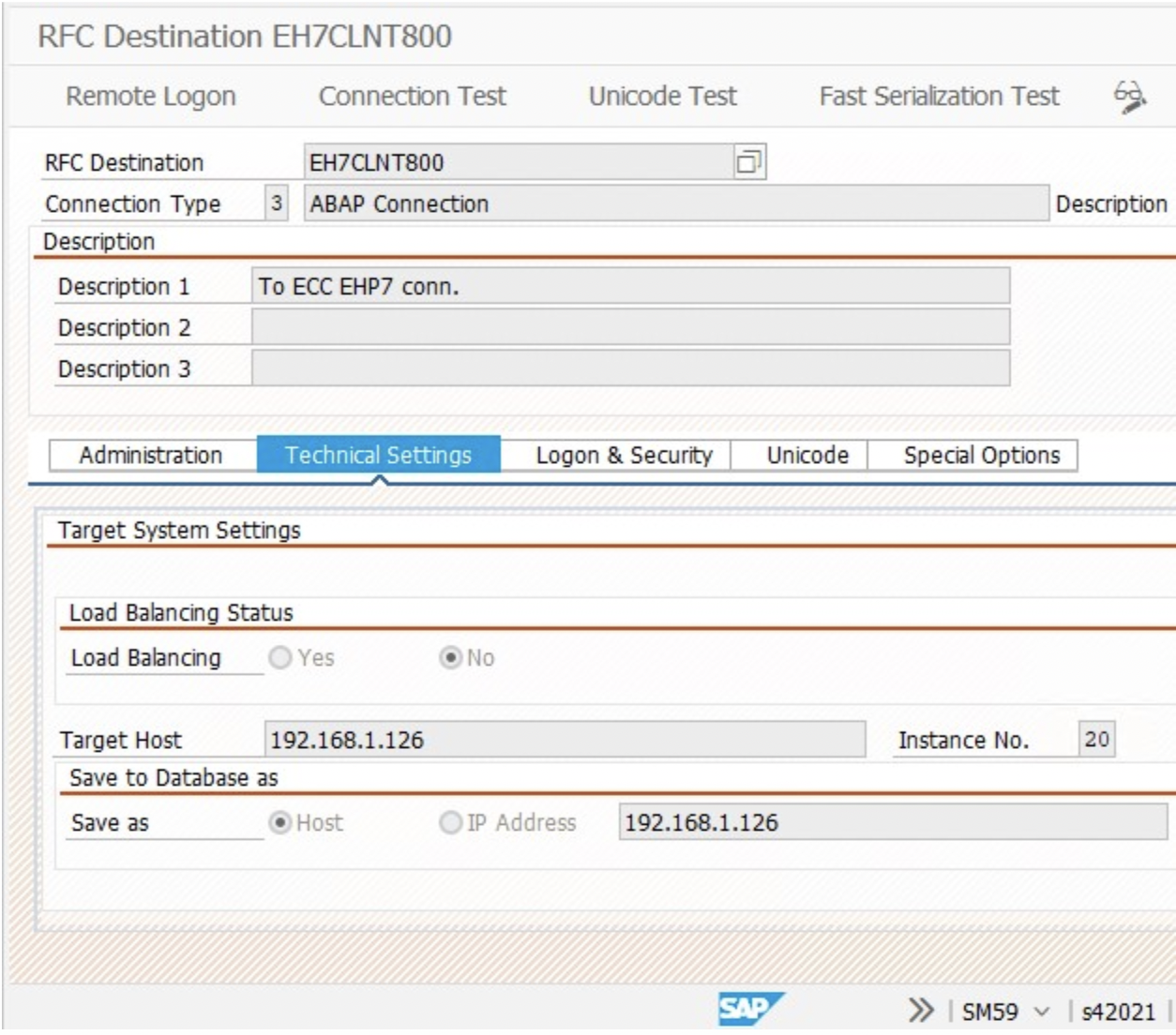
2. Similarly, create 2 more RFC connections from SLT to ECC
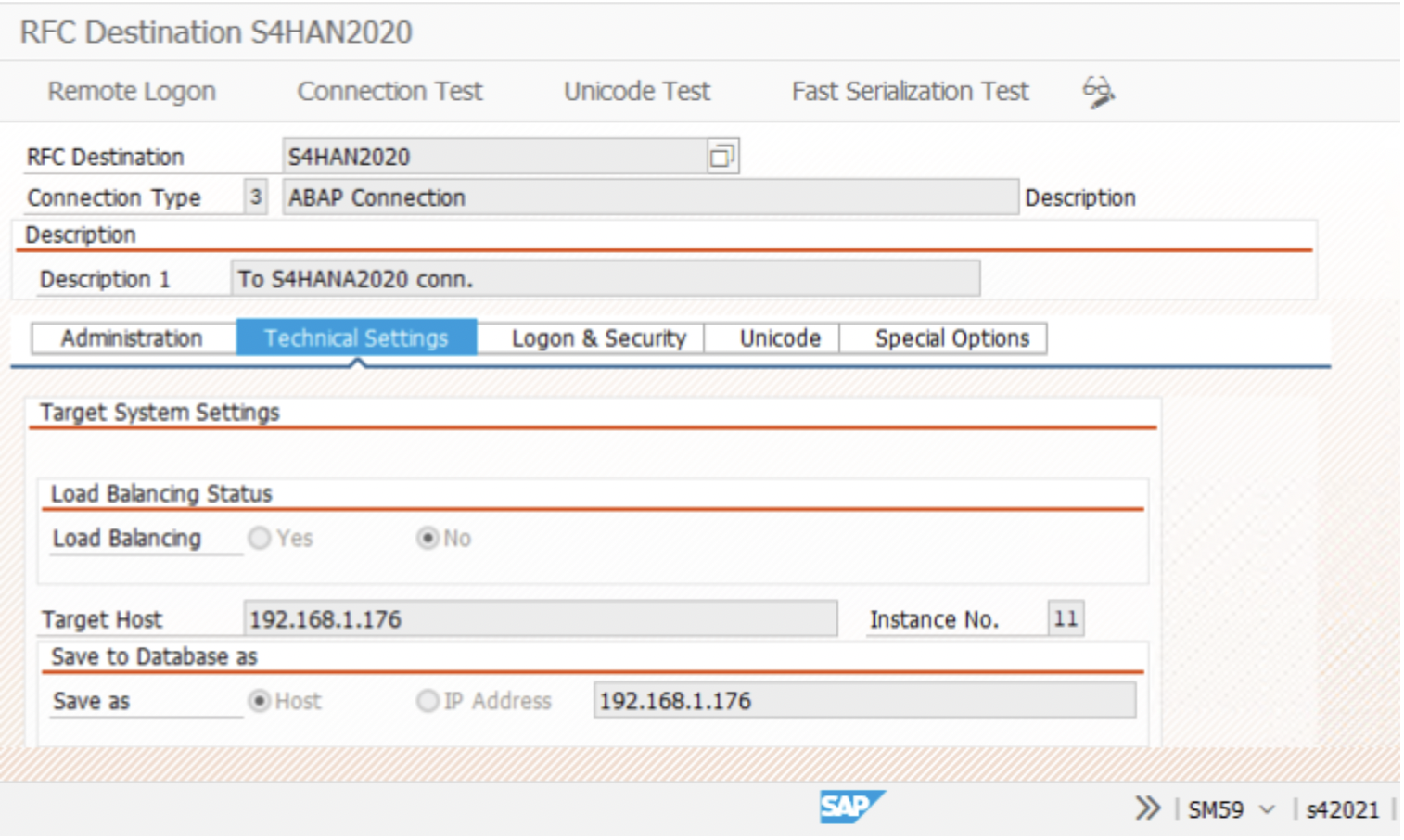
3. and then, an SLT-Local connection.
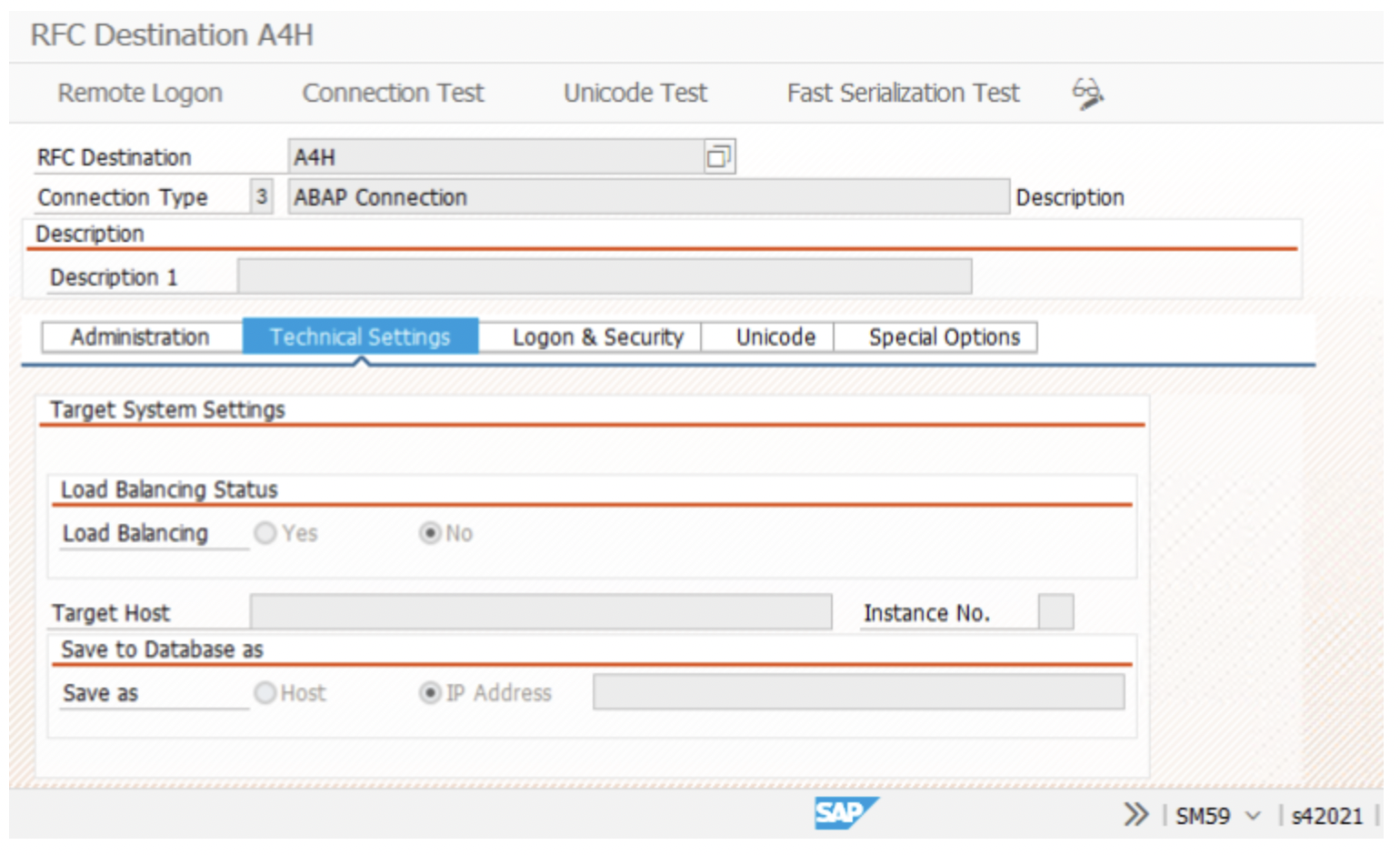
SLT System Configuration:
- Use transaction DBCO to create SLT to target system( HANA Enterprise ) connection. The target connection will be a DB Connection. HANA Enterprise systems do not support the RFC connection. Also, DB connection can help to create tables SPFLI, SFLIGHT in the target system without manual intervention.
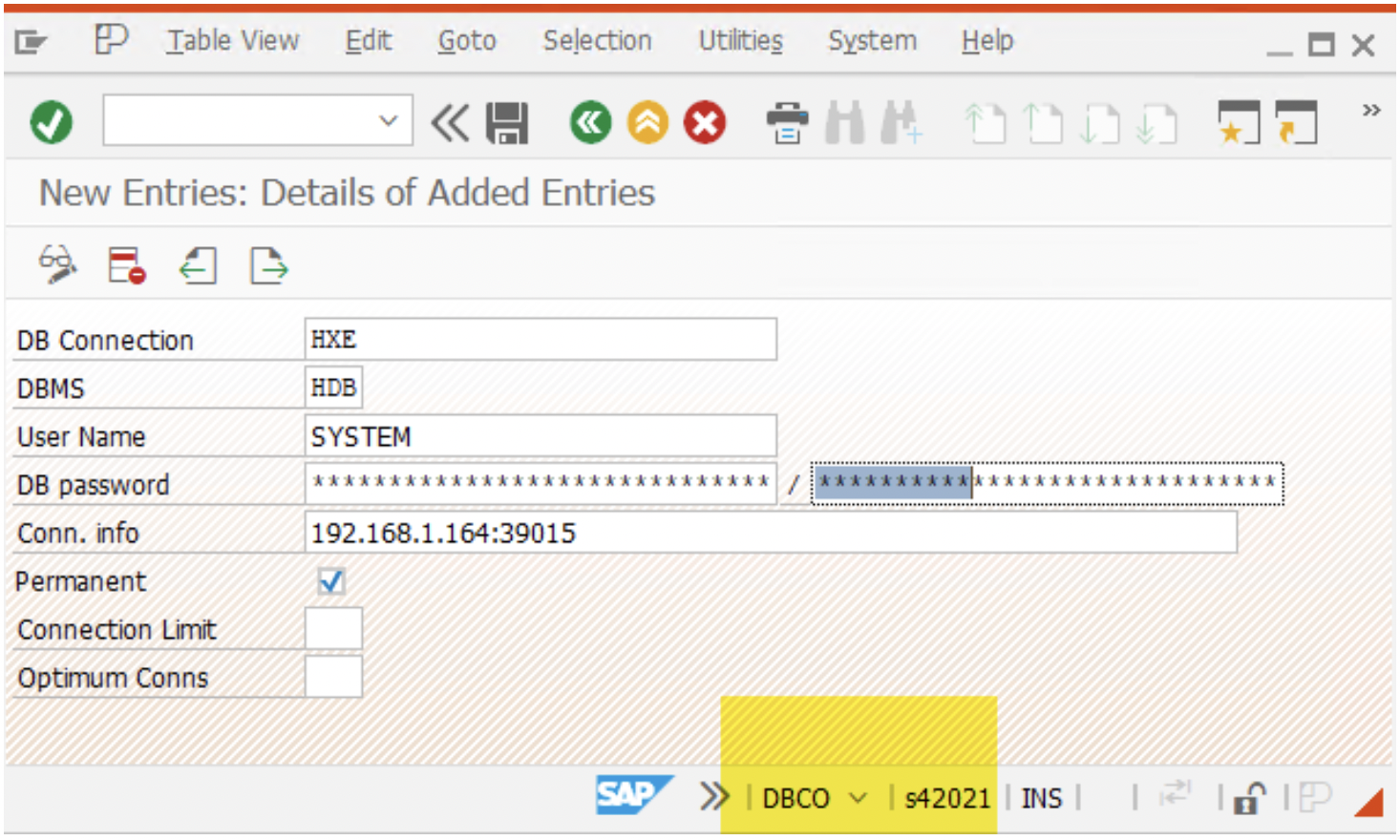
2. We create a configuration object in the SLT system for each source system by using transaction LTRC. The configuration object contains the source system connection details, such as the system ID, client ID, and login credentials. We must also specify each source system’s database connection parameters( created above ).
To add the other two source systems and replicate their data to the same target schema, you need to follow these steps:
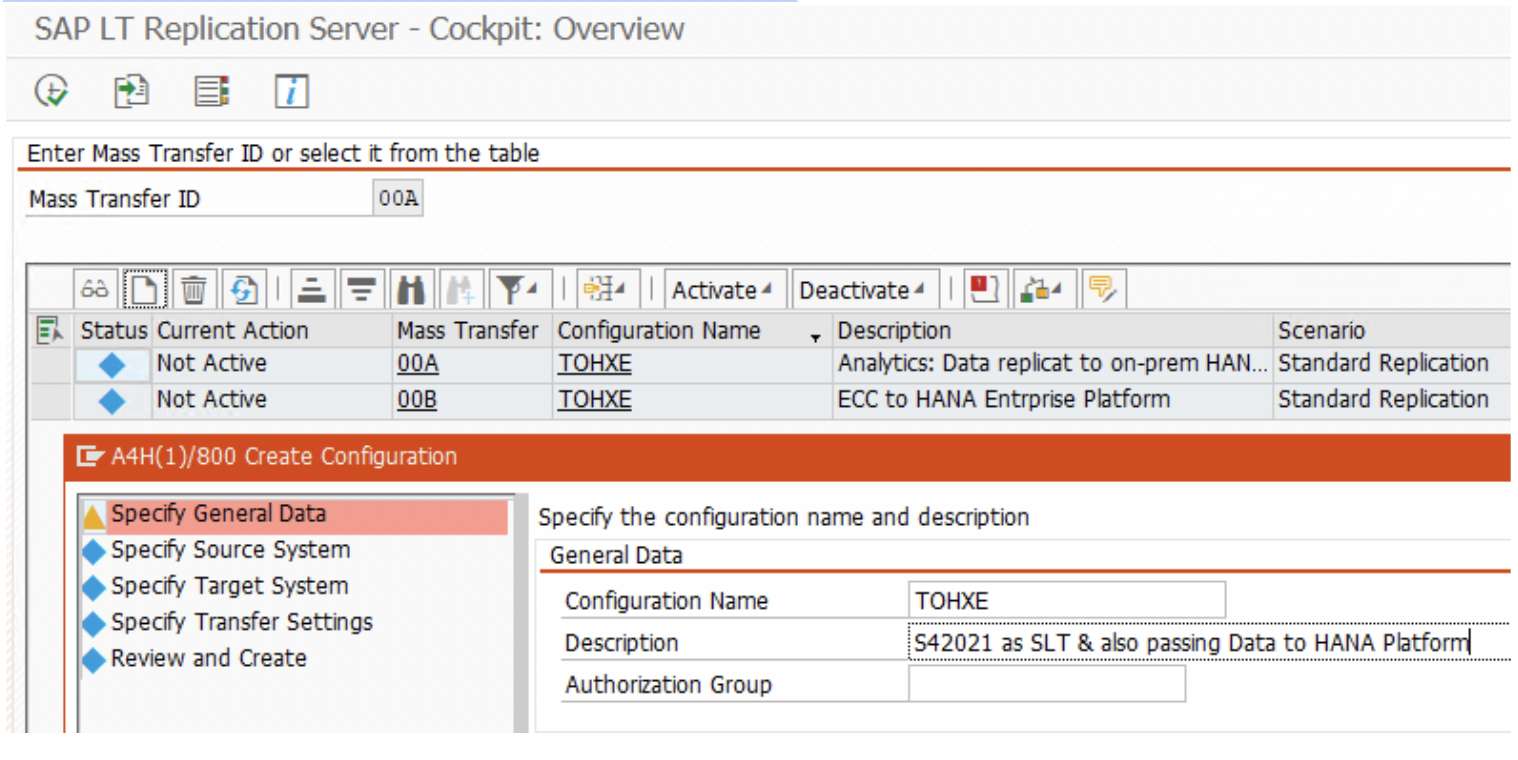
- Log in to the SLT system and launch the transaction LTRC. Create a new configuration by clicking on the “New Configuration” button.
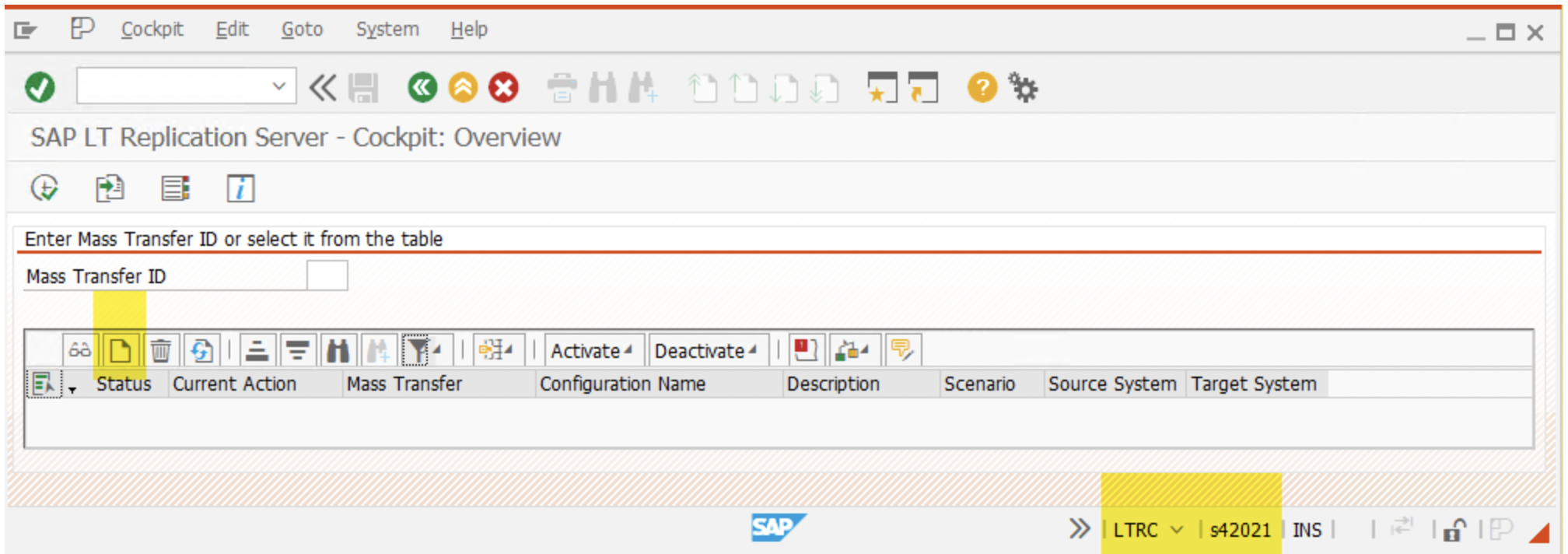
2. In the “Create Configuration” section, give a meaningful name to the ‘Configuration Name’. Though not mandatory, this name used again in the remaining 2 Mass-Transfer ID( MT_ID) creations. It helps to identify related MT_IDs.
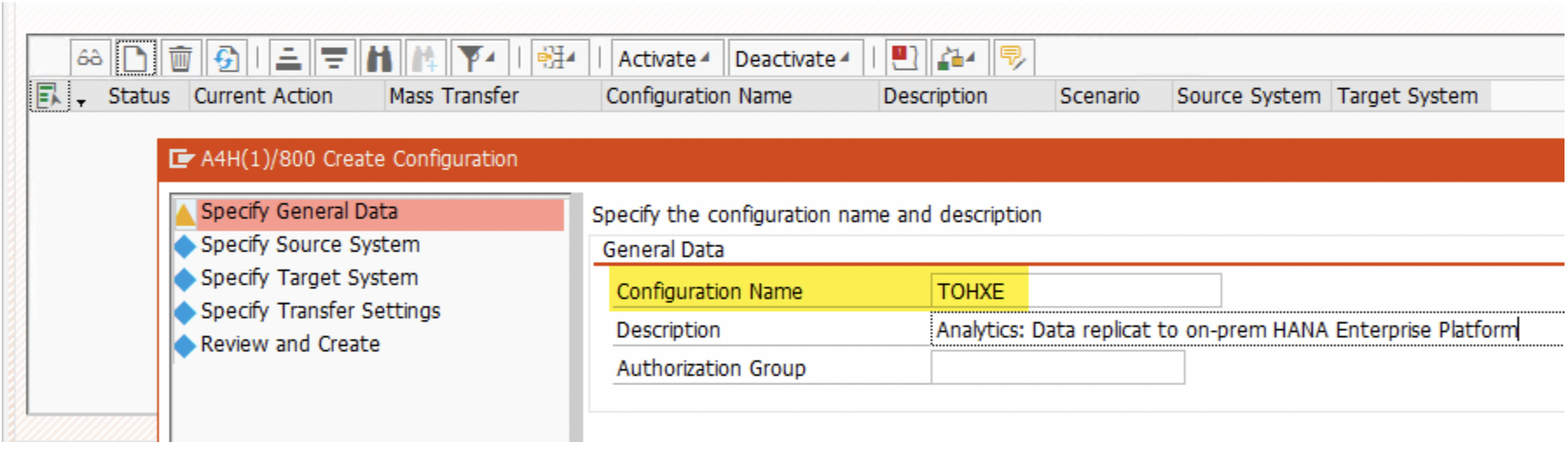
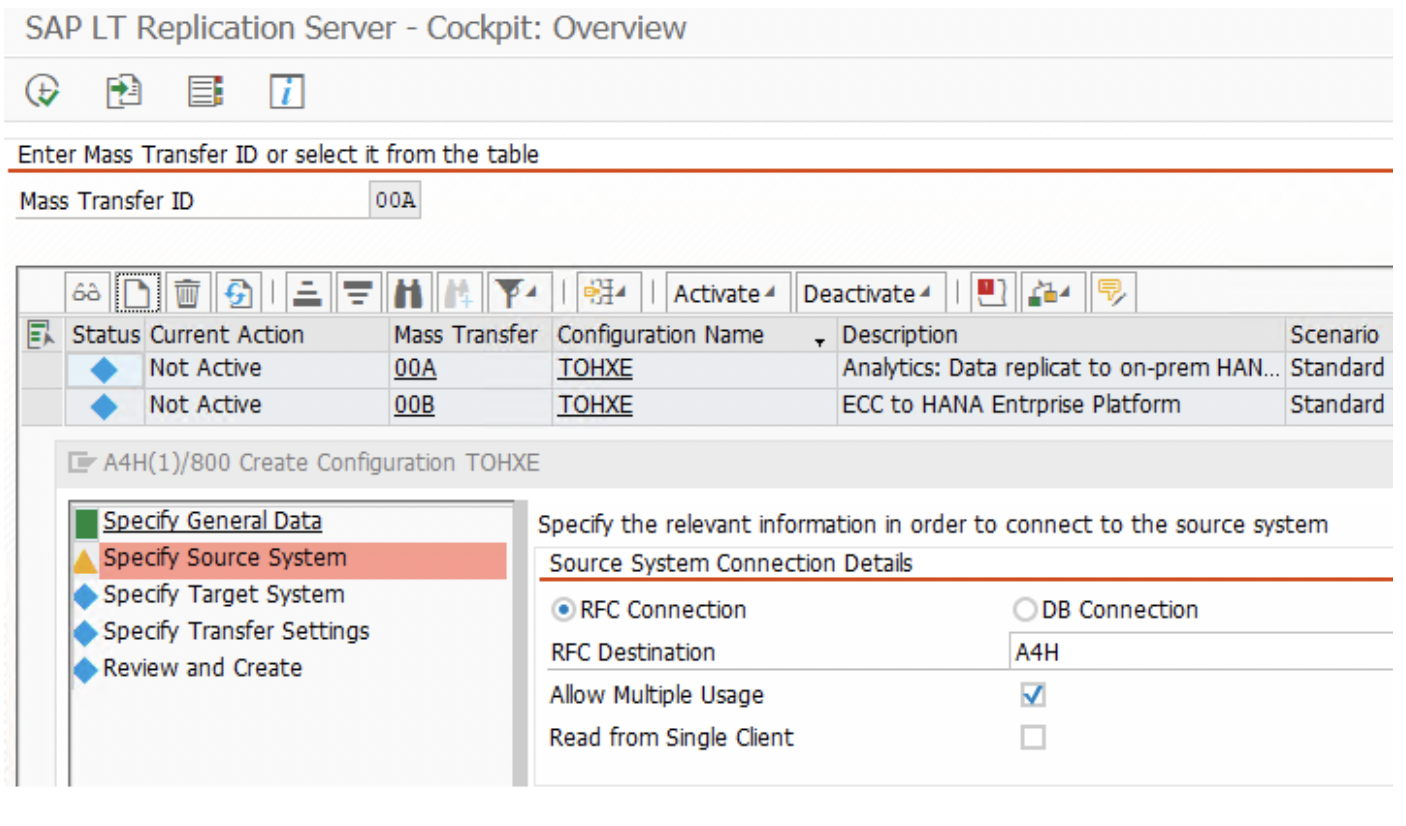
3. In the ‘Source System’ section, choose the “RFC Connection” radio button. All of our source systems are connected via RFC. Give the Source RFC name created in the SLT-server i.e. S42021 system. Here it is S4HAN2020.
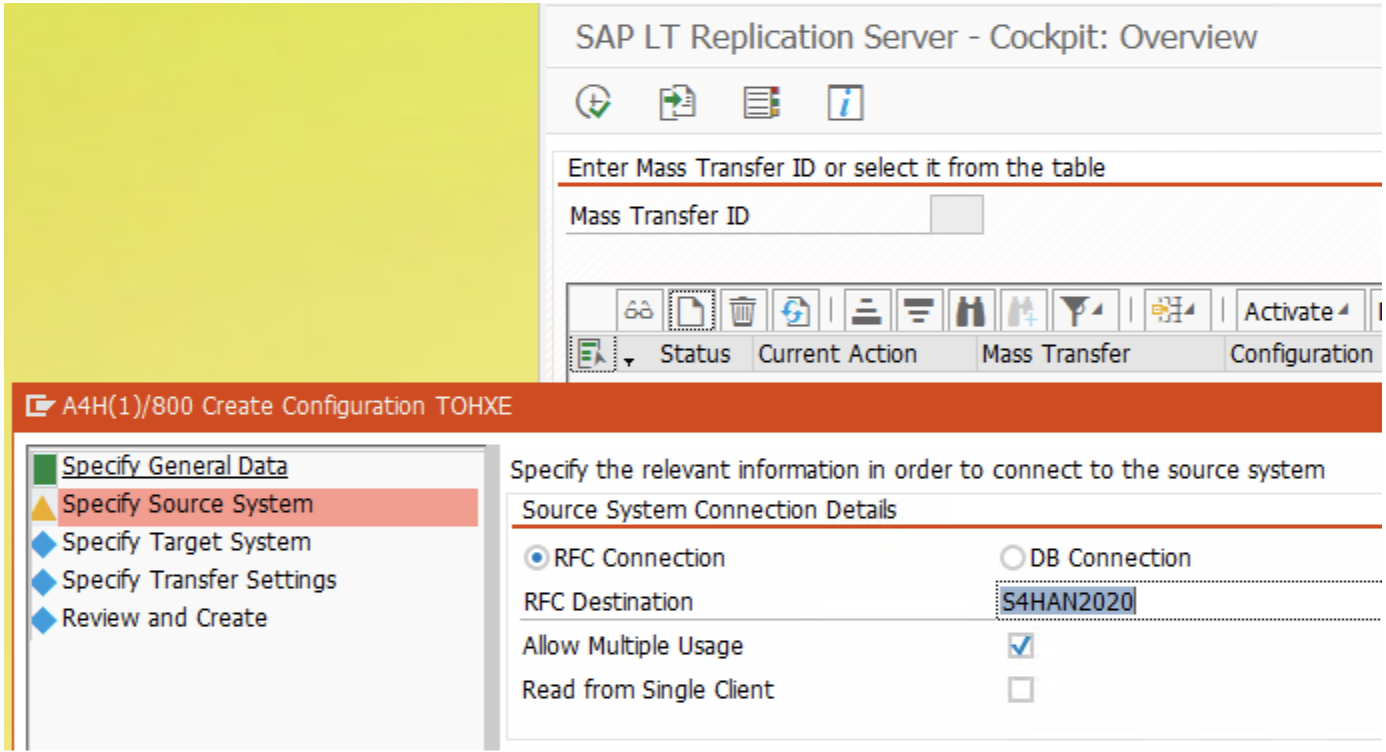
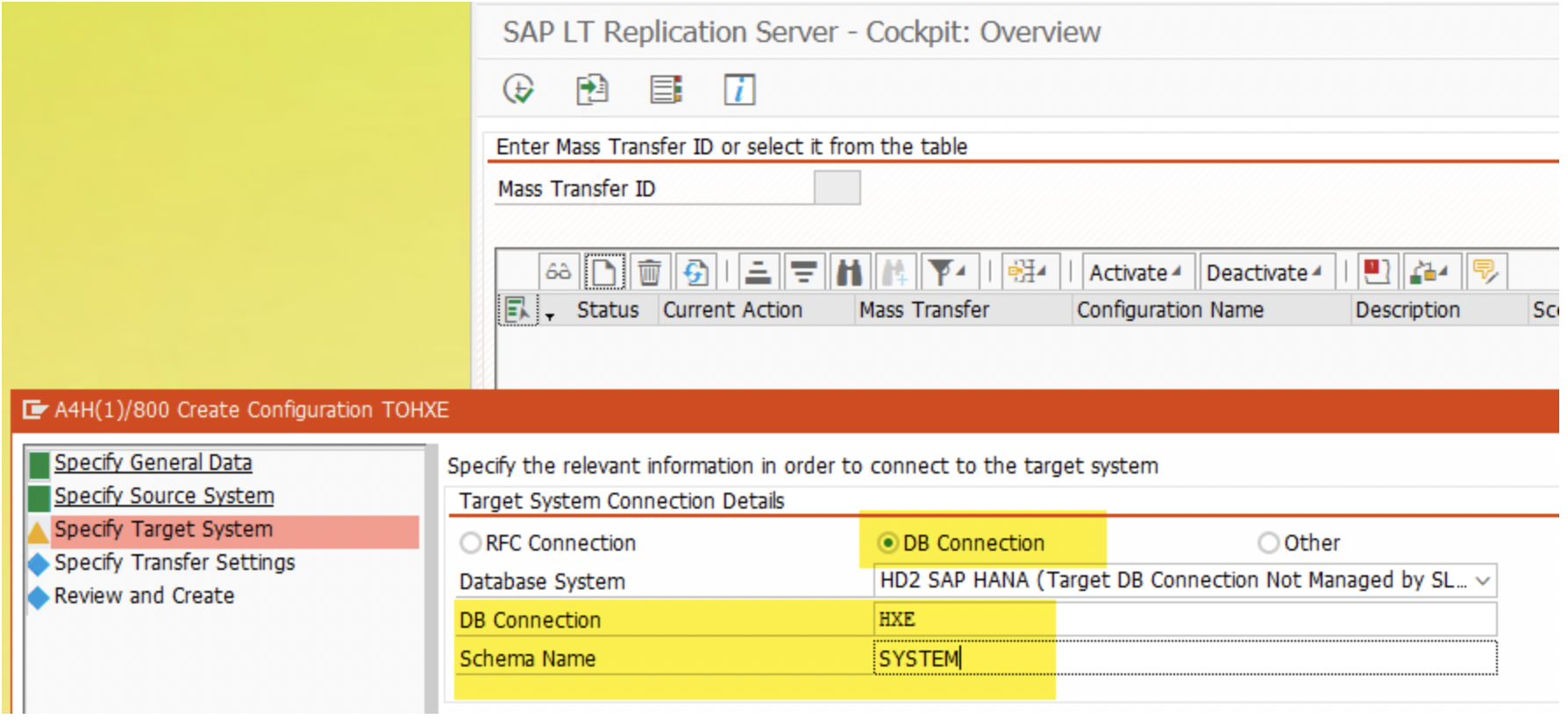
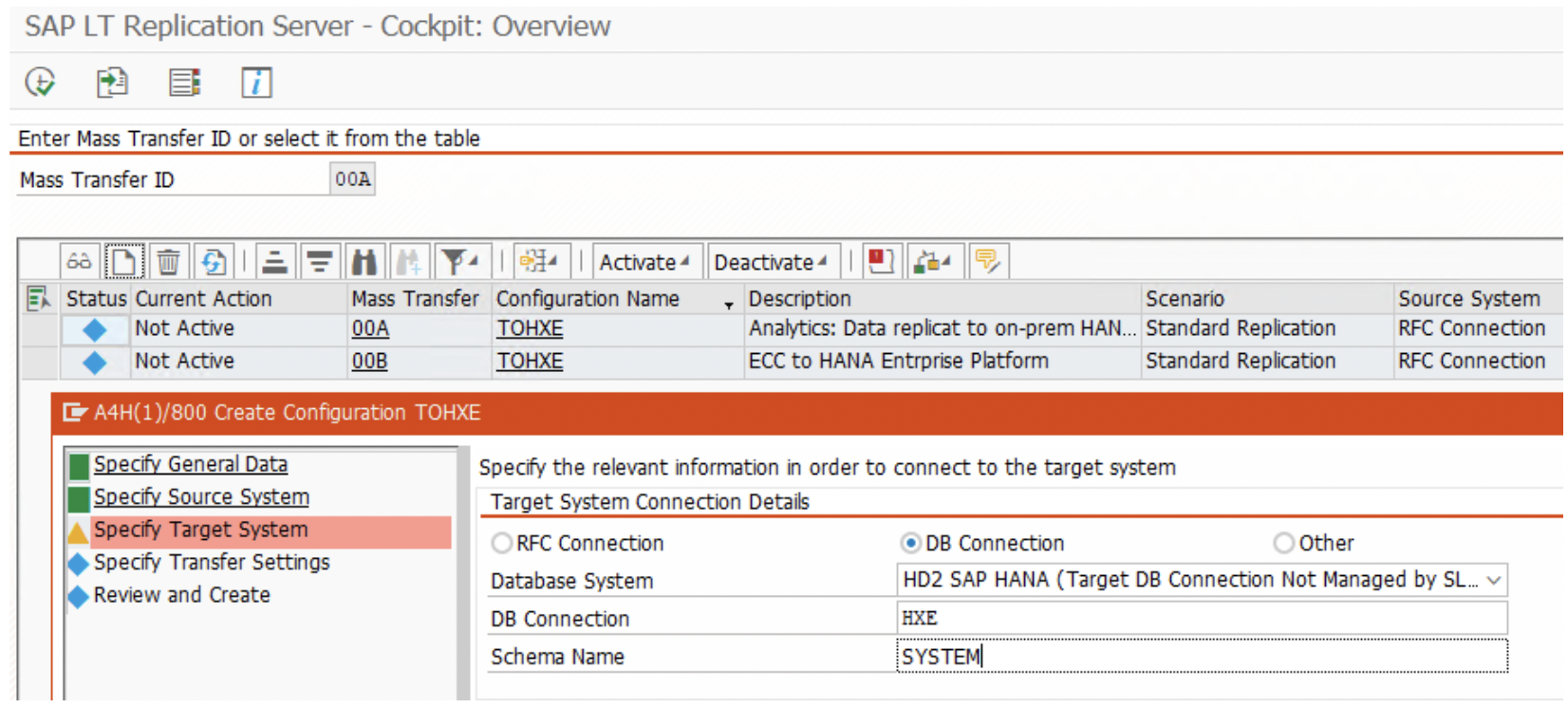
4. In the ‘Target System’ section, choose the “DB Connection” radio-button and enter the details created from the DBCO transaction.
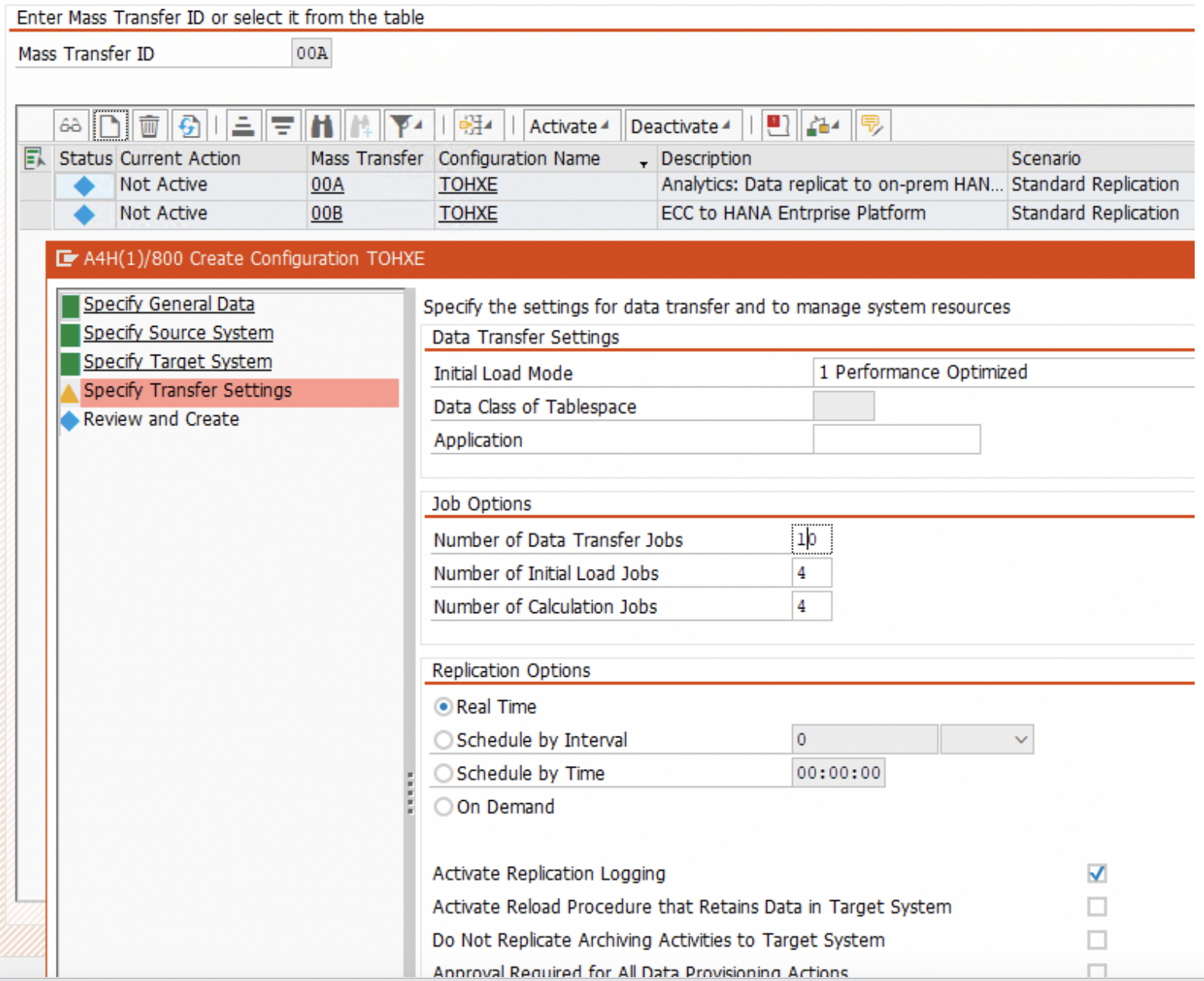
5. Next, choose “Real Time” radio button, and Replication Logging checkbox options.
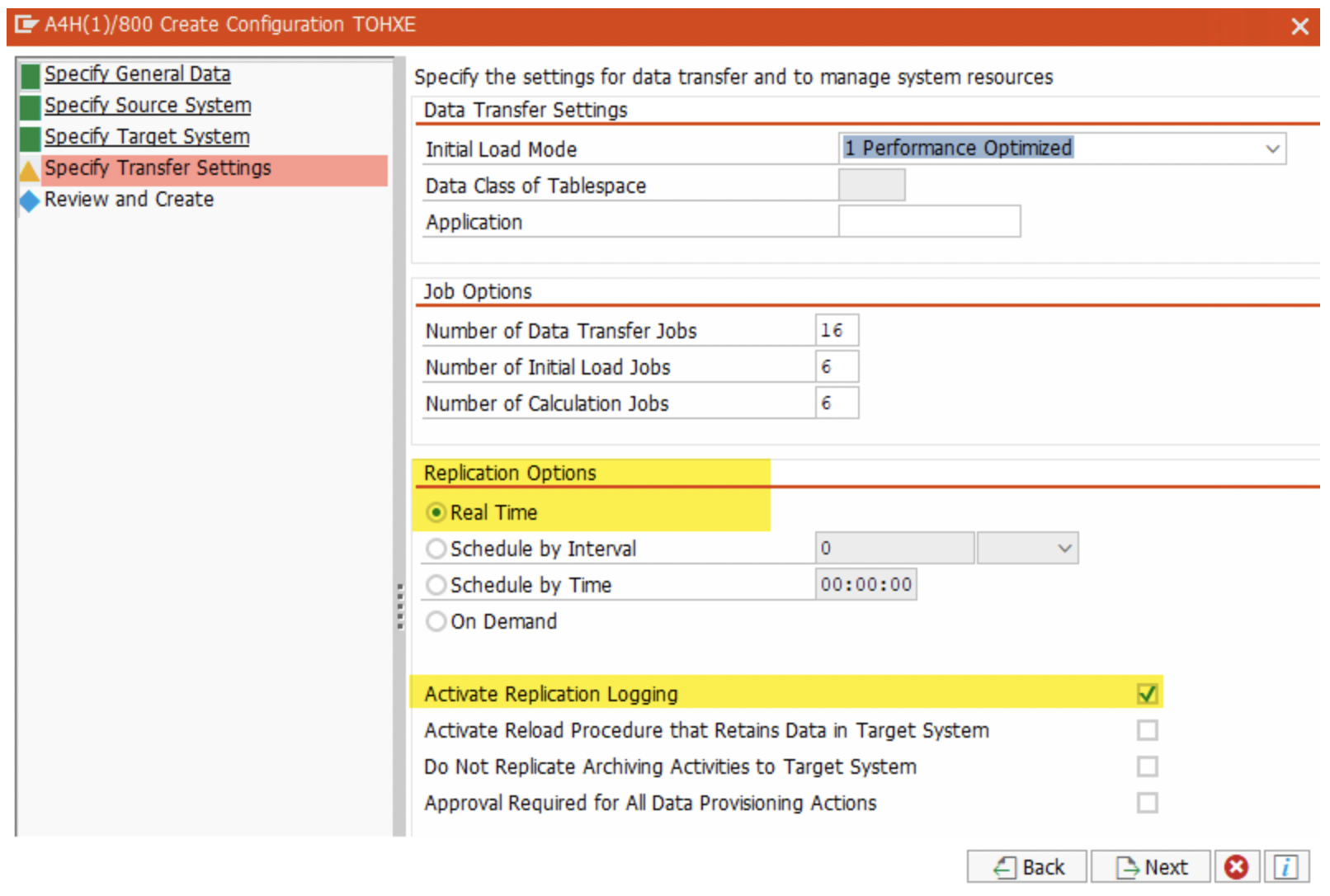
6. Review and click on ‘Create’.
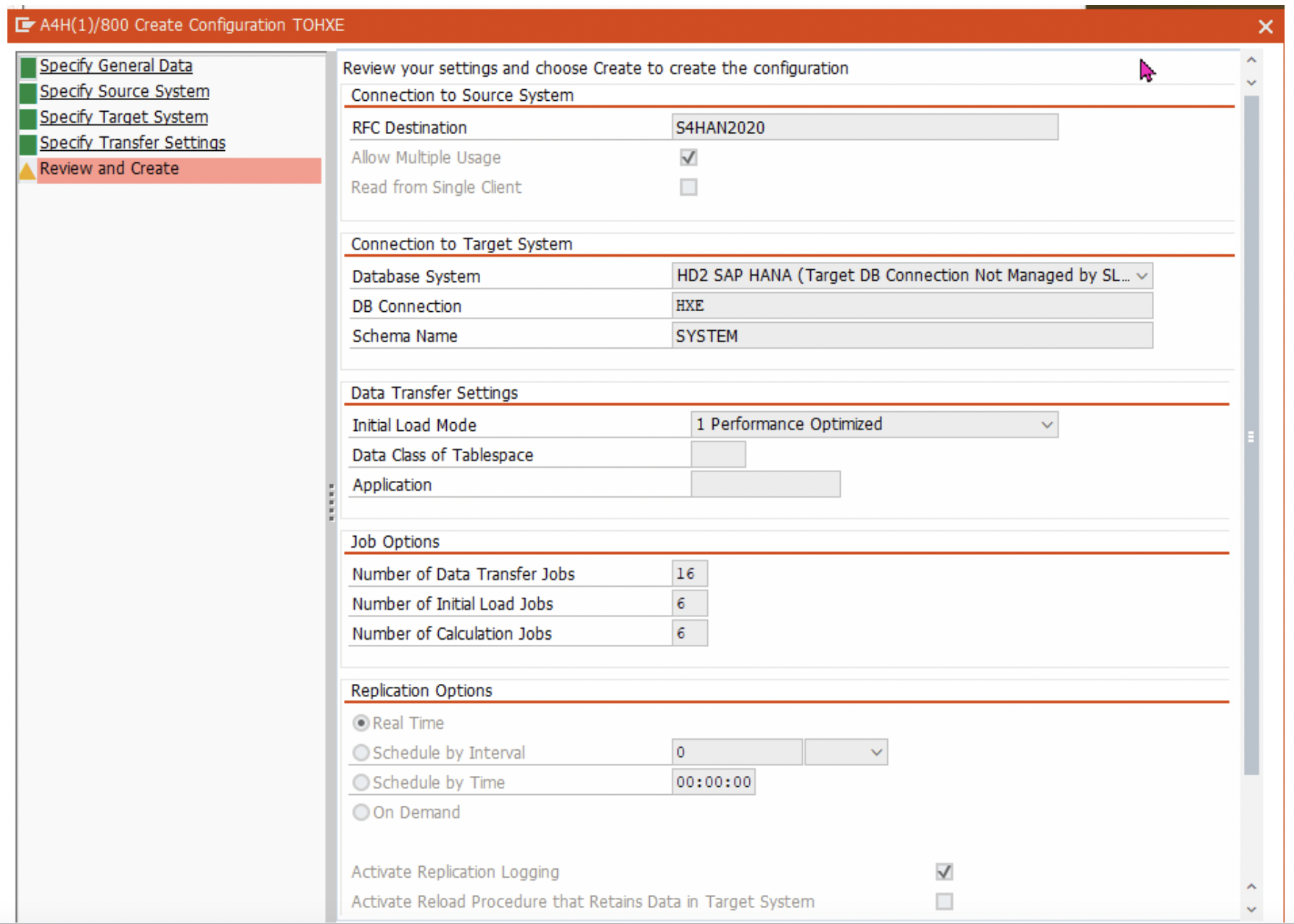
7. Repeat step 1 to 4 for the other two source systems as well. When adding the other source systems, make sure you choose the same target schema ( SYSTEM ) as in step 4.
Similarly, for ECC Mass-Transfer ID connection-
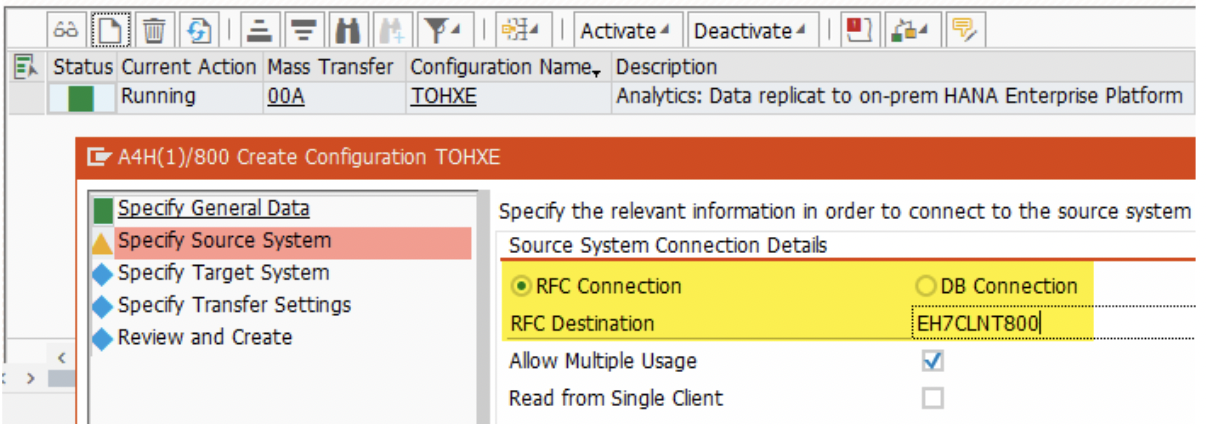
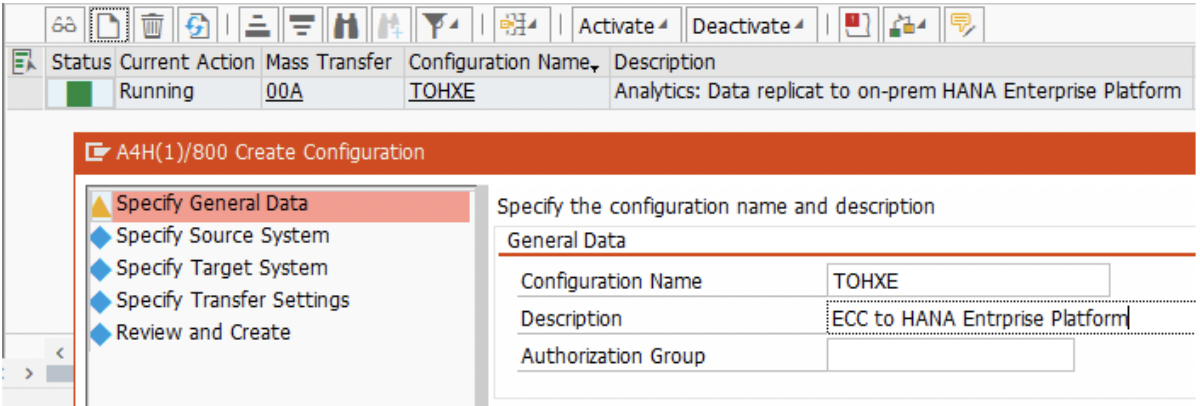
*Notice the schema name. It is identical to the above schema name. It is key to replicate all source into single target table.
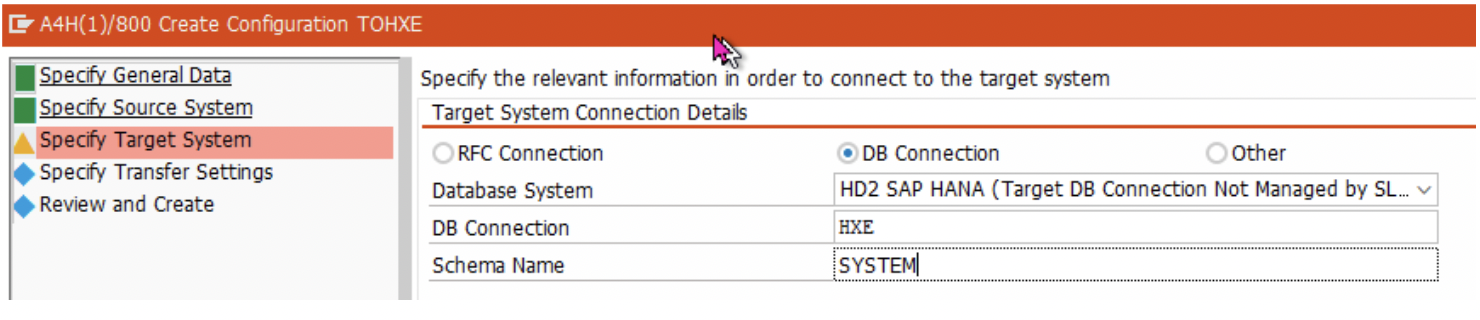
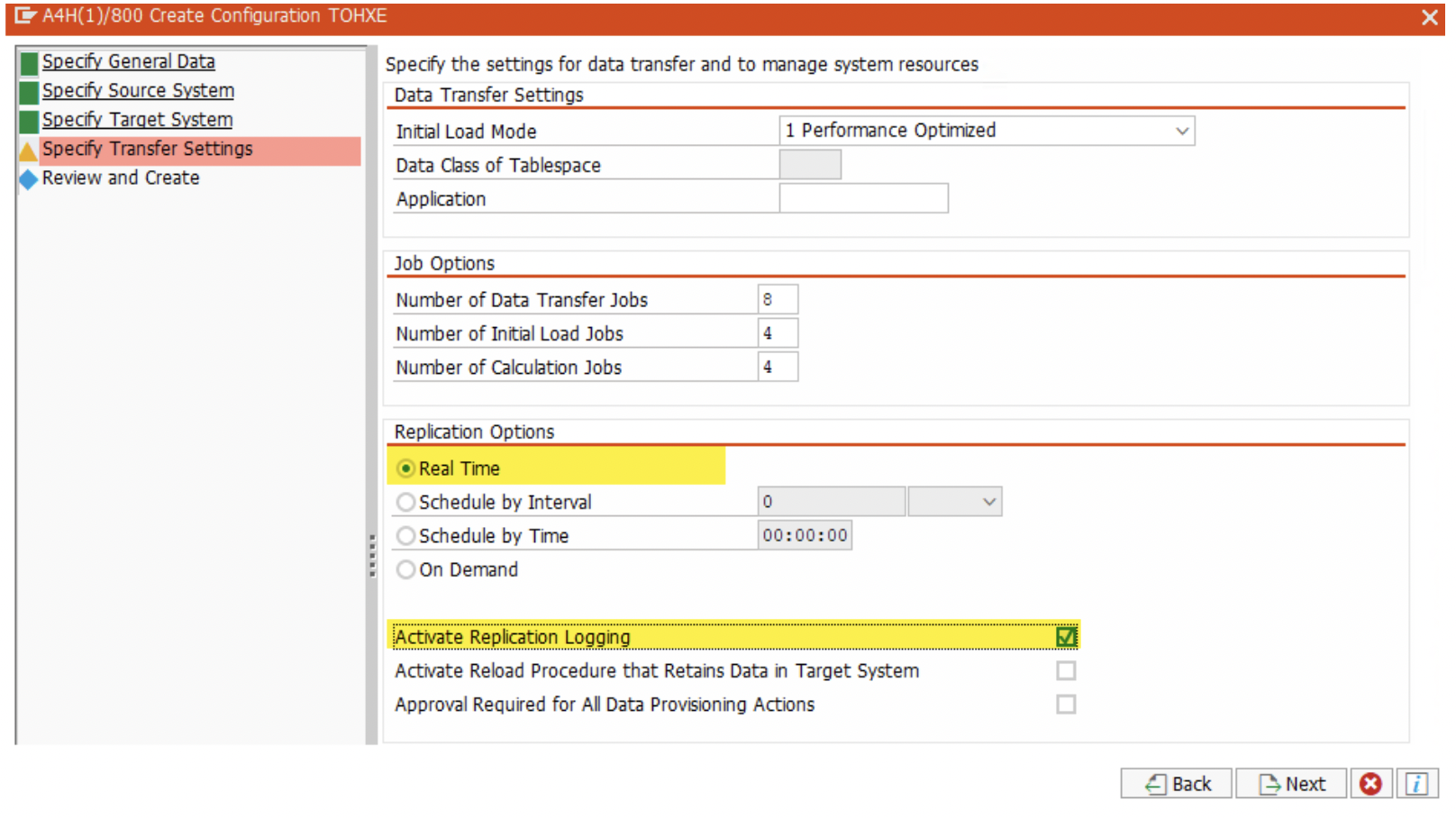
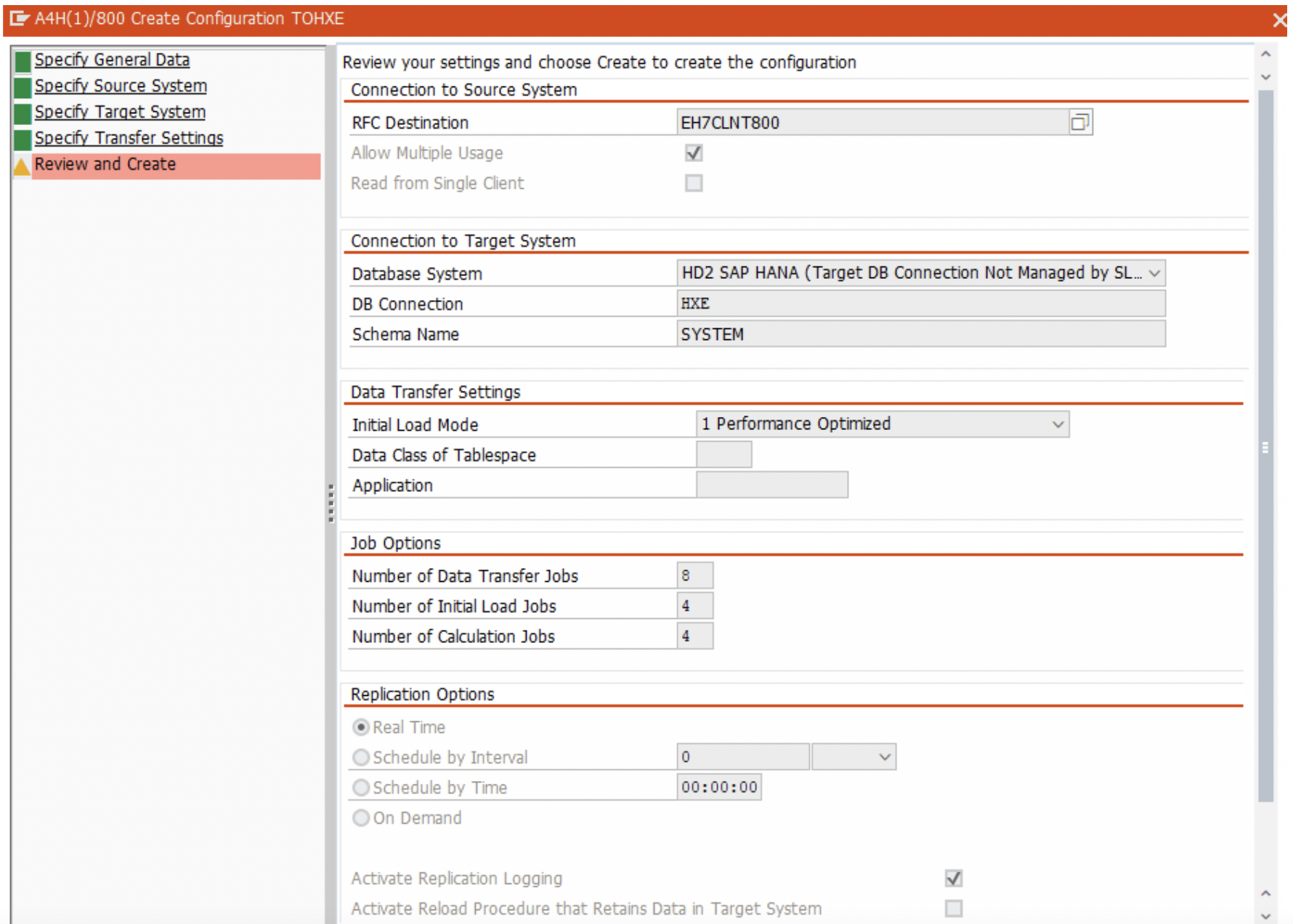
Similarly, for S42021 Mass-Transfer ID connection-
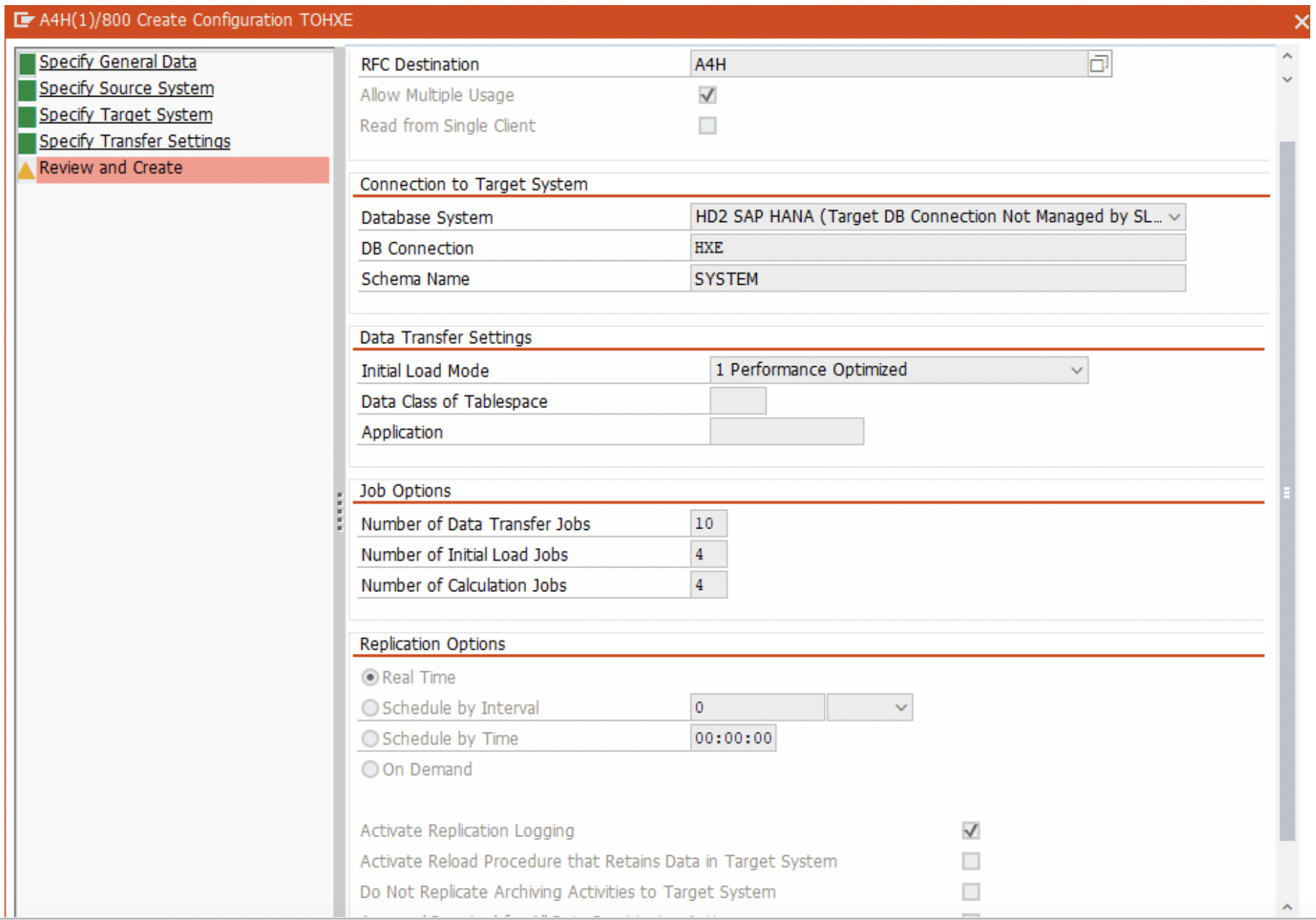
8. Click on the “Activate” button to activate the configuration. Once the source system configuration is complete, we can replicate tables from the source systems to the target system.
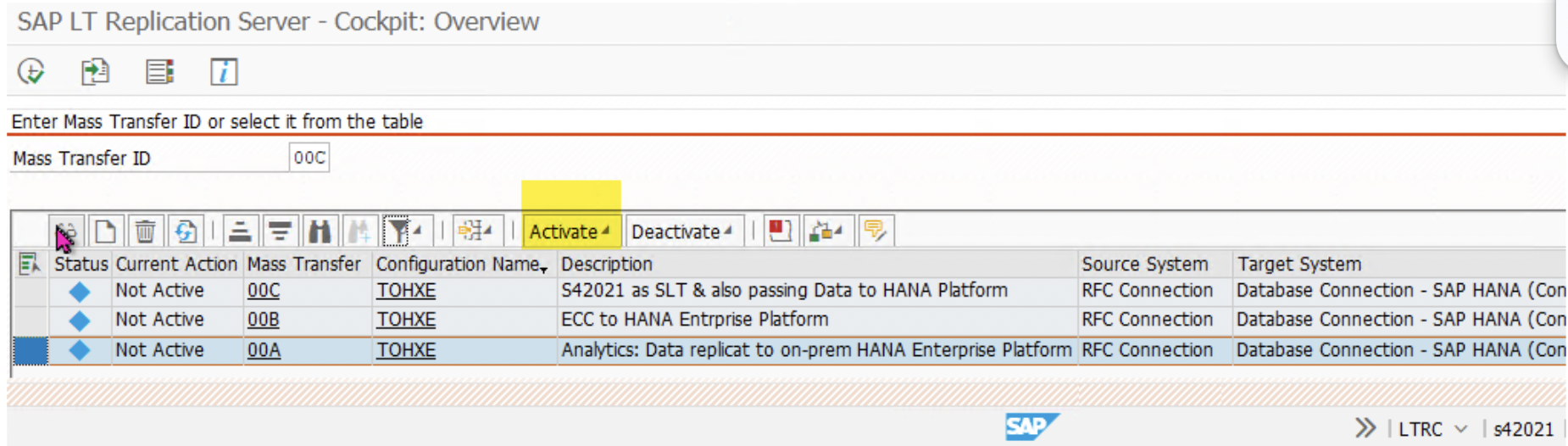
Table Replication:
In this demo, we will replicate the SPFLI, SFLIGHT table definition and additional columns and data to the target HANA database’s schema SYSTEM. We will use additional columns ZZSYSOURCE in the tables to track the data source system.
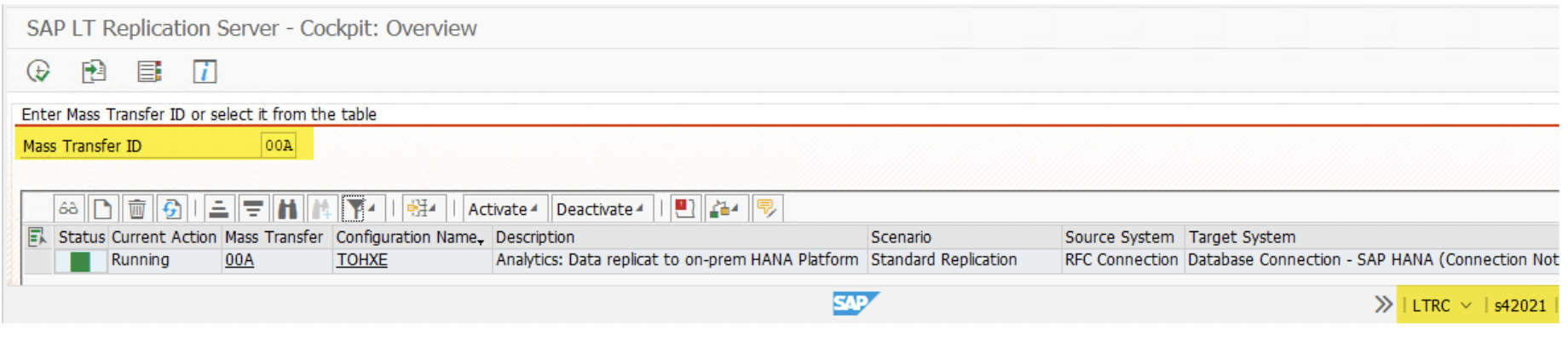
- After activation, go to the LTRS transaction and select the Mass Transfer ID that was created in step III i.e ‘00C’, ‘00B’, ‘00A’.
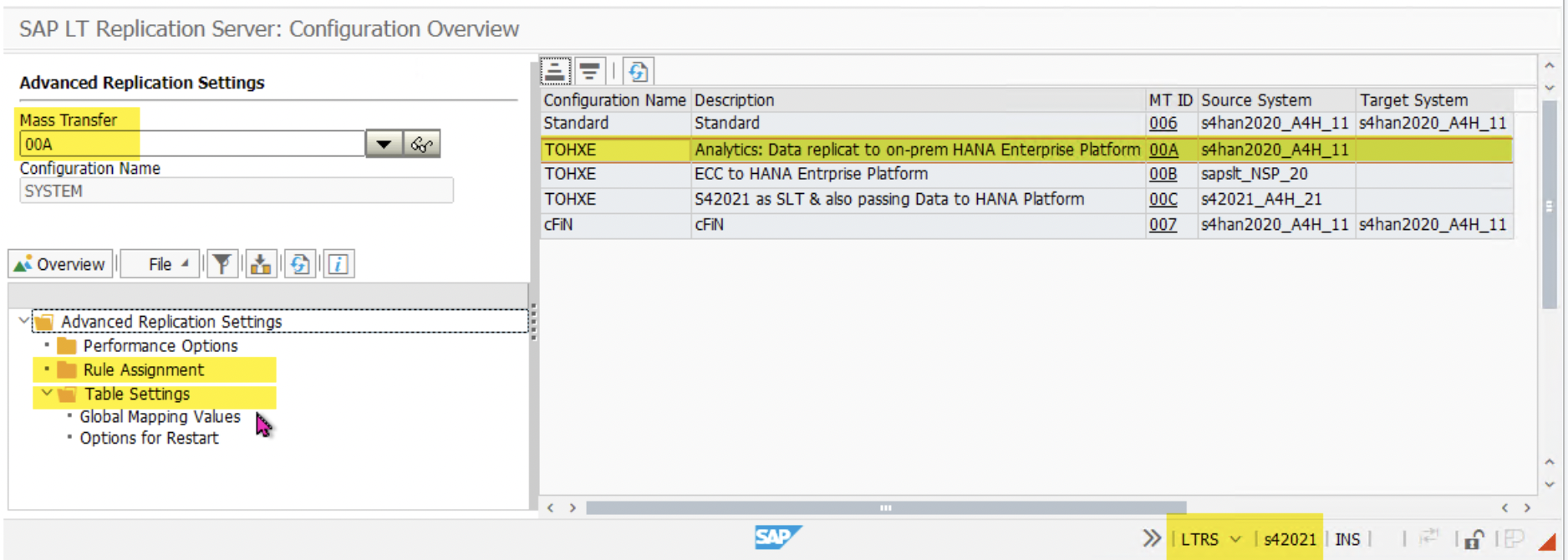
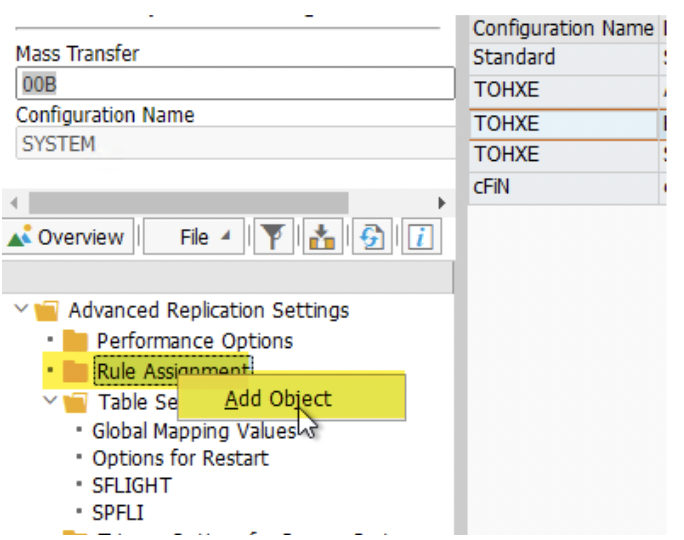
2. Right click on the ‘Table Setting’ and ‘Add Object’ to include tables.
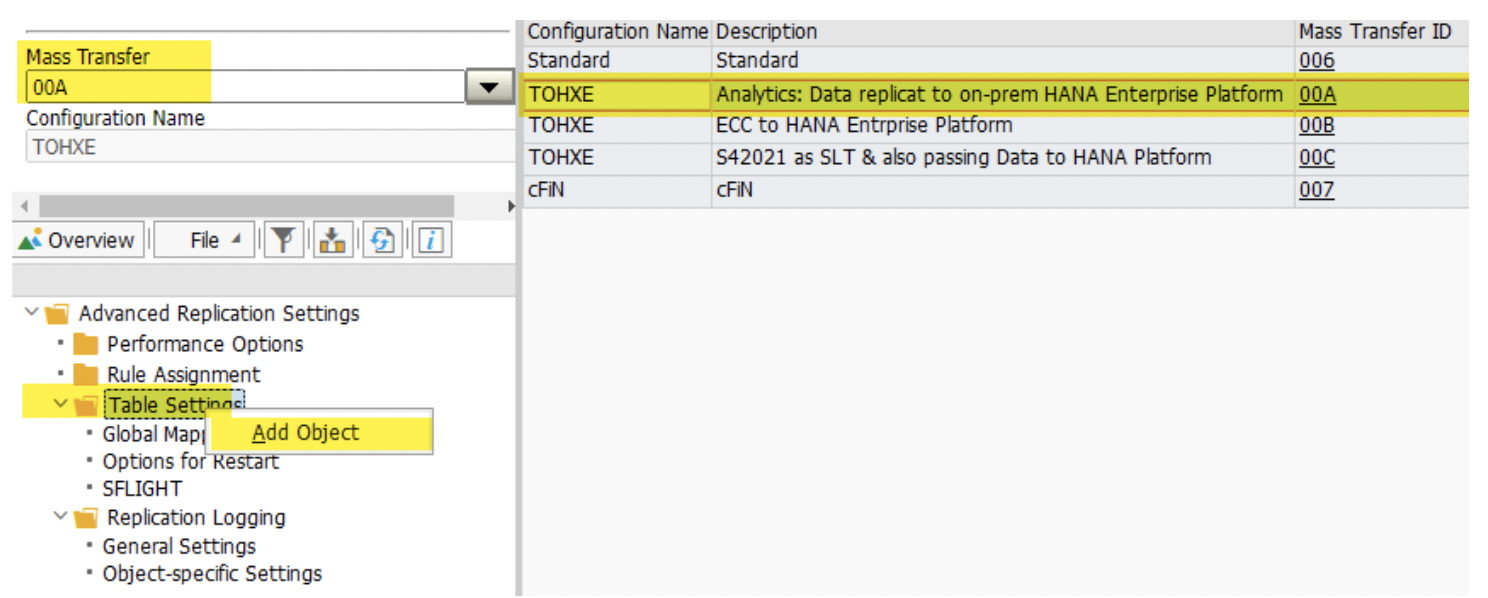
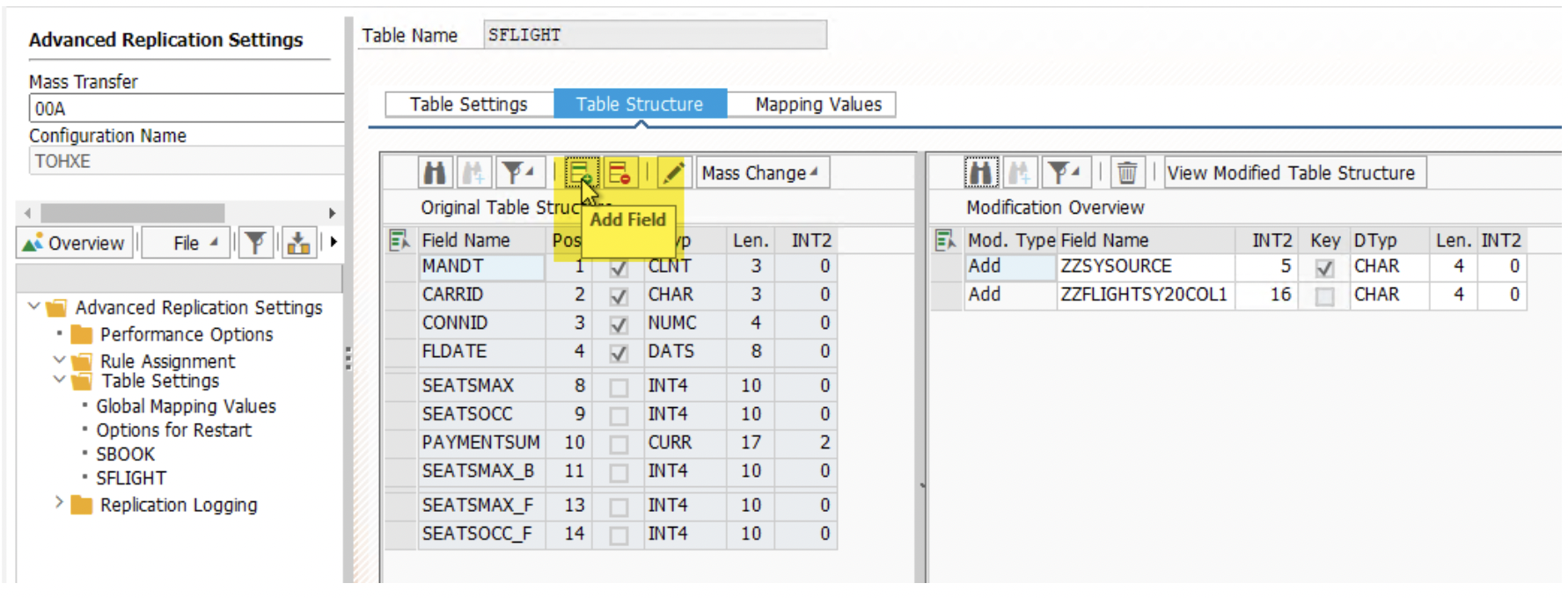
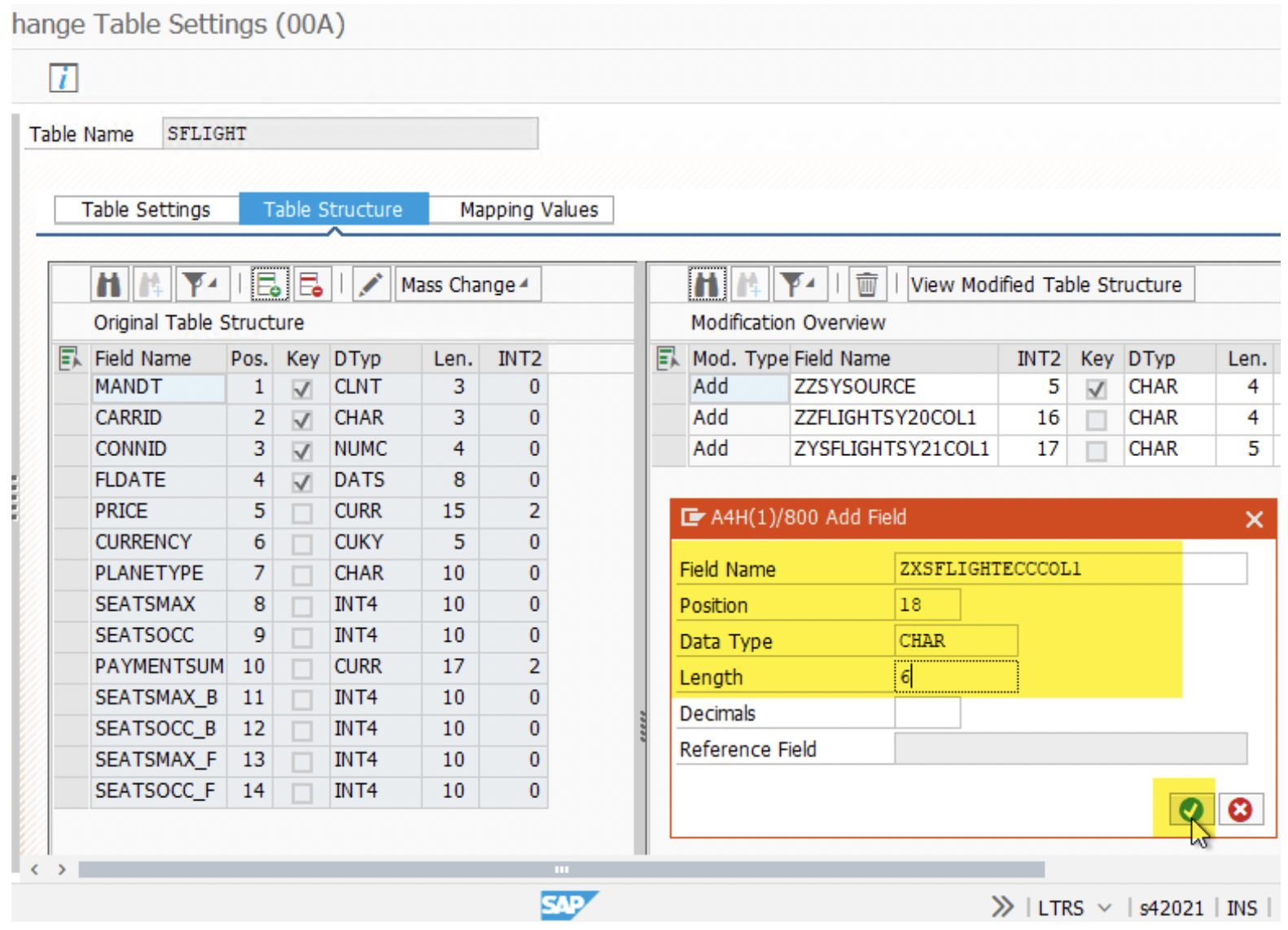
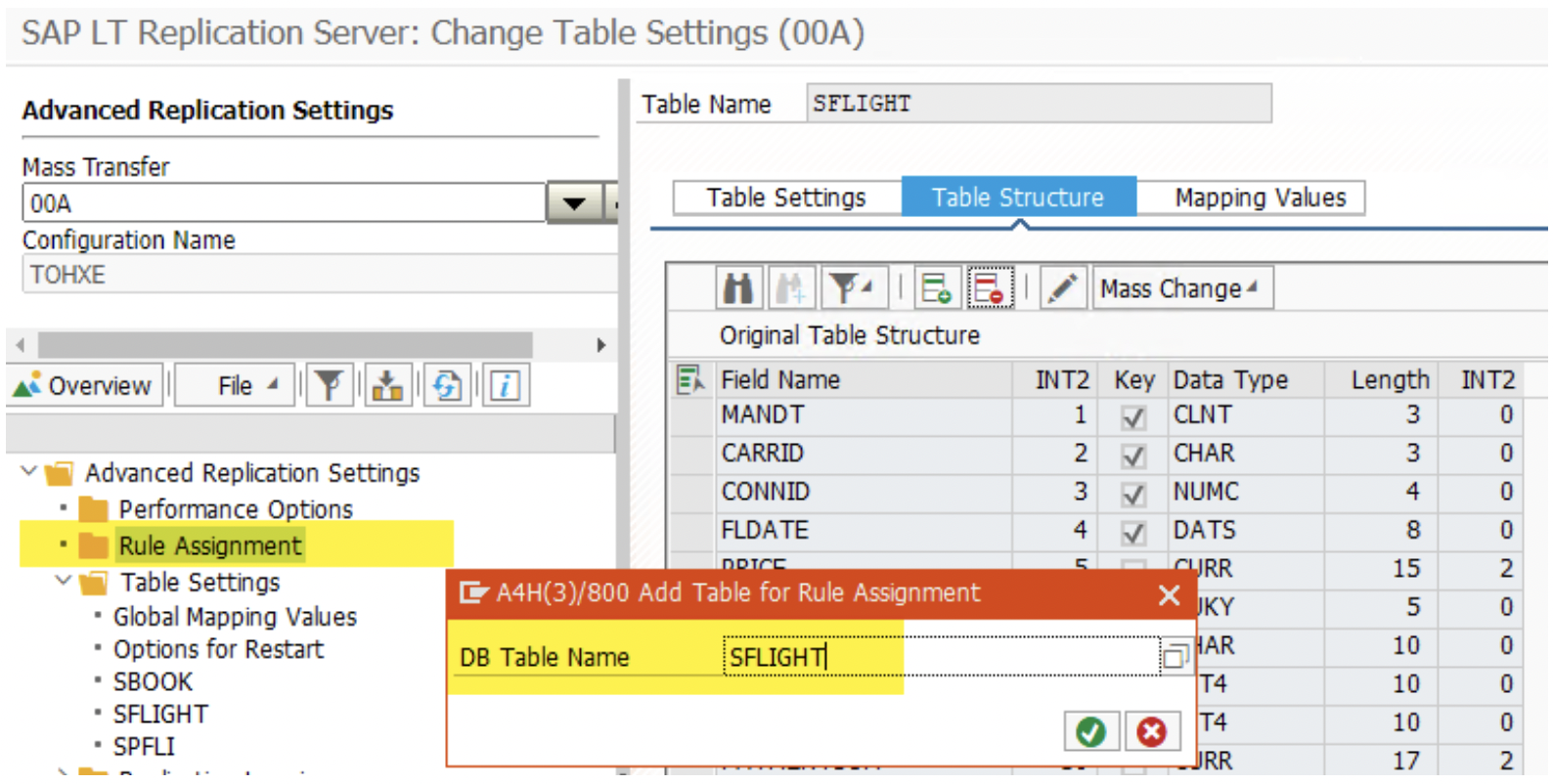
3. Add fields by clicking on the green icon. We could include ZZSYSOURCE and other fields. Please note that tables must have the same structure in all 3 Mass Transfer ID.
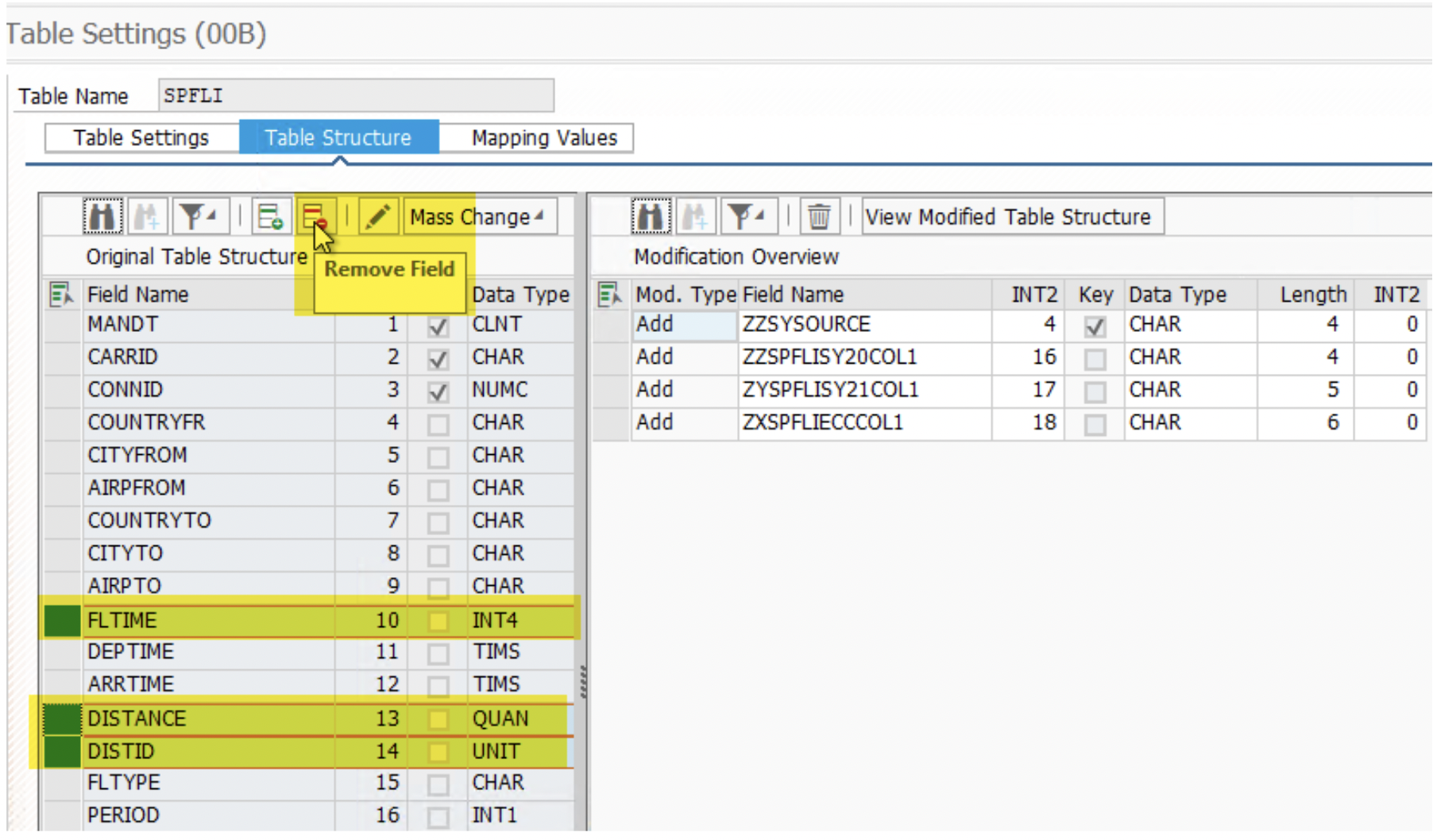
4. You can also remove the fields you do not want to replicate to the target schema. Again, it must be done in all 3 Mass Transfer IDs.
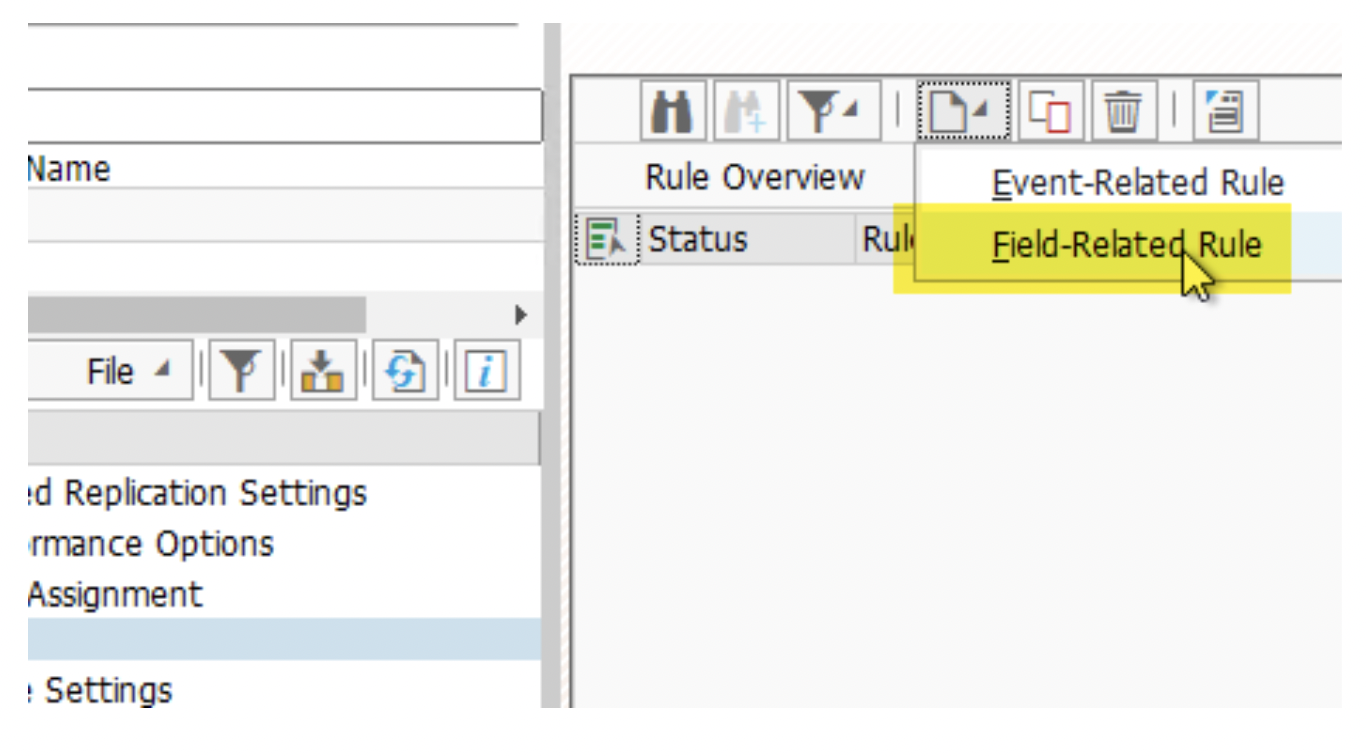
5. Now create the ‘Rule Assignment’ to fill the ‘ZZSYSOURCE’ field to track the source system. For ECC, we have given the value ‘ECC’. Similarly, for S42021 it is ‘2021’ and for S4HAN2020, it is ‘2020’.
Also, this activity shall be carried out for all tables and all Mass Transfer IDs.
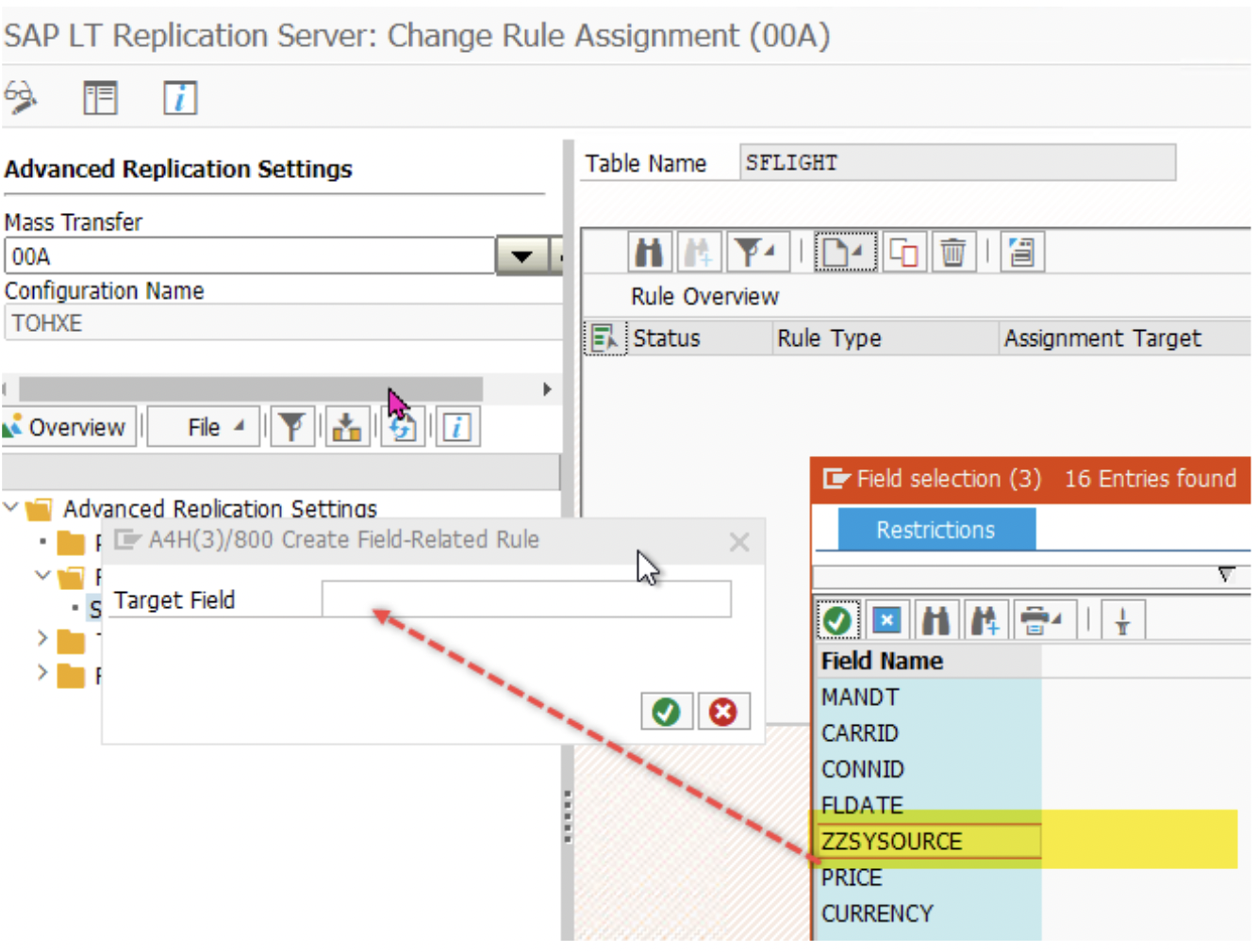
Give the value in ‘Import Parameter 1’. It must be within a single quote. It is available as an ‘I_P1’ parameter. Also, column ‘ZZSYSOURCE’ should be prefixed with ‘E_’ and written as ‘E_ZZSYSOURCE’. If the logic to determine the field value is complex then use ‘Include Name’ and use an include to process the login.
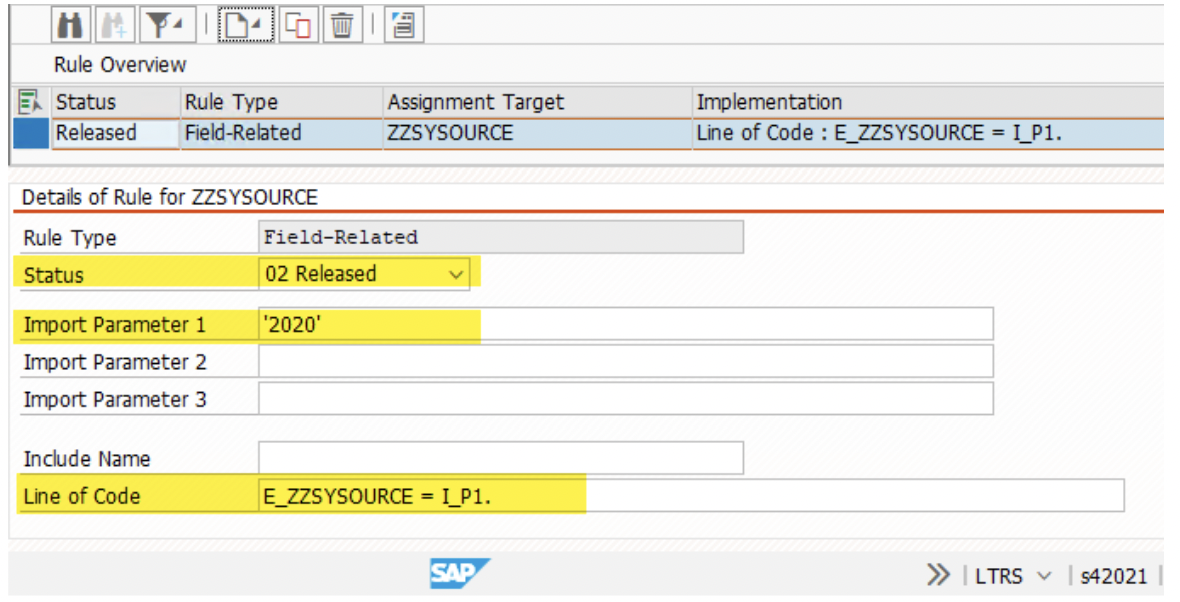
*NOTE: All 3 Mass-Transfer ID( MT_ID) must have the identical fields in a table. A column need not be filled by all 3 source systems. However, it must be a part of the table structure in all 3 MT_IDs.
Data Replication:
Once the table setting and Rule Assignment are complete, we can start the data replication process. Repeat the below steps for the other two Mass Transfer IDs.
Note: Mass Transfer ID may not be identical across the screenshots. But it is trivial and can be ignored. Each MT_ID shall follow the same steps.
- The respective Mass Transfer ID will be activated to copy the source schema data to the target schema. Run transaction ‘LTRC,’ select relevant MT_ID , and click ‘Activate.’ It shall turn into a green square.
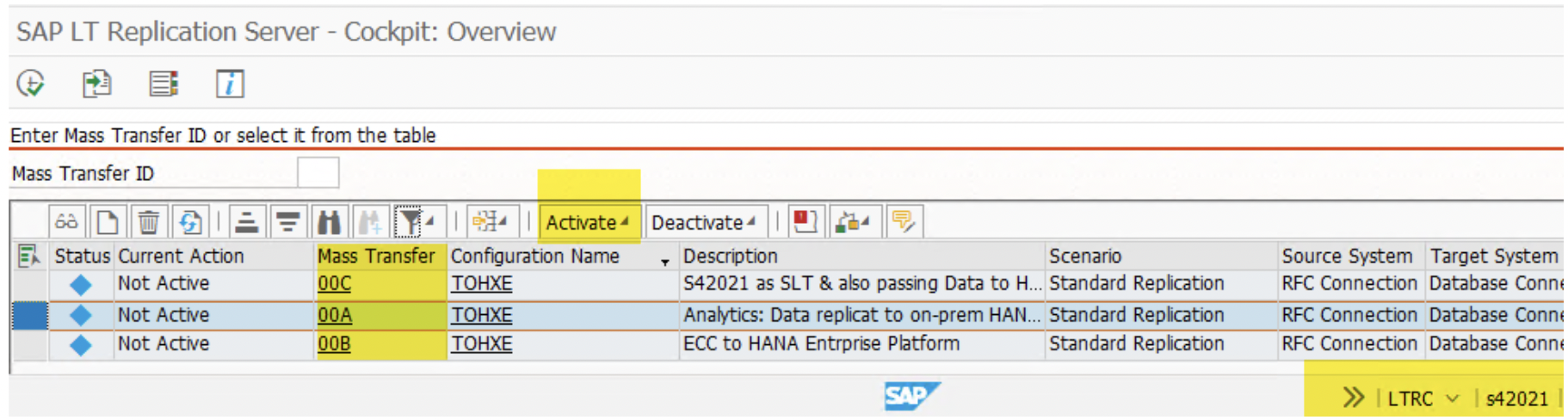
2. Click on the MT_ID i.e. ‘00A’. On the next screen, click on ‘Data Provisioning’.
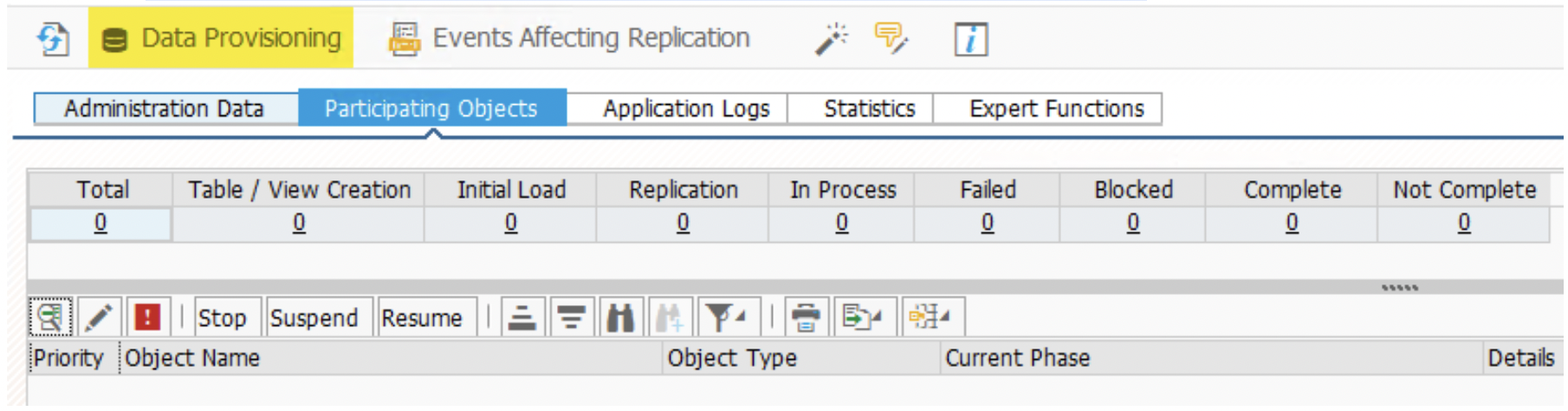
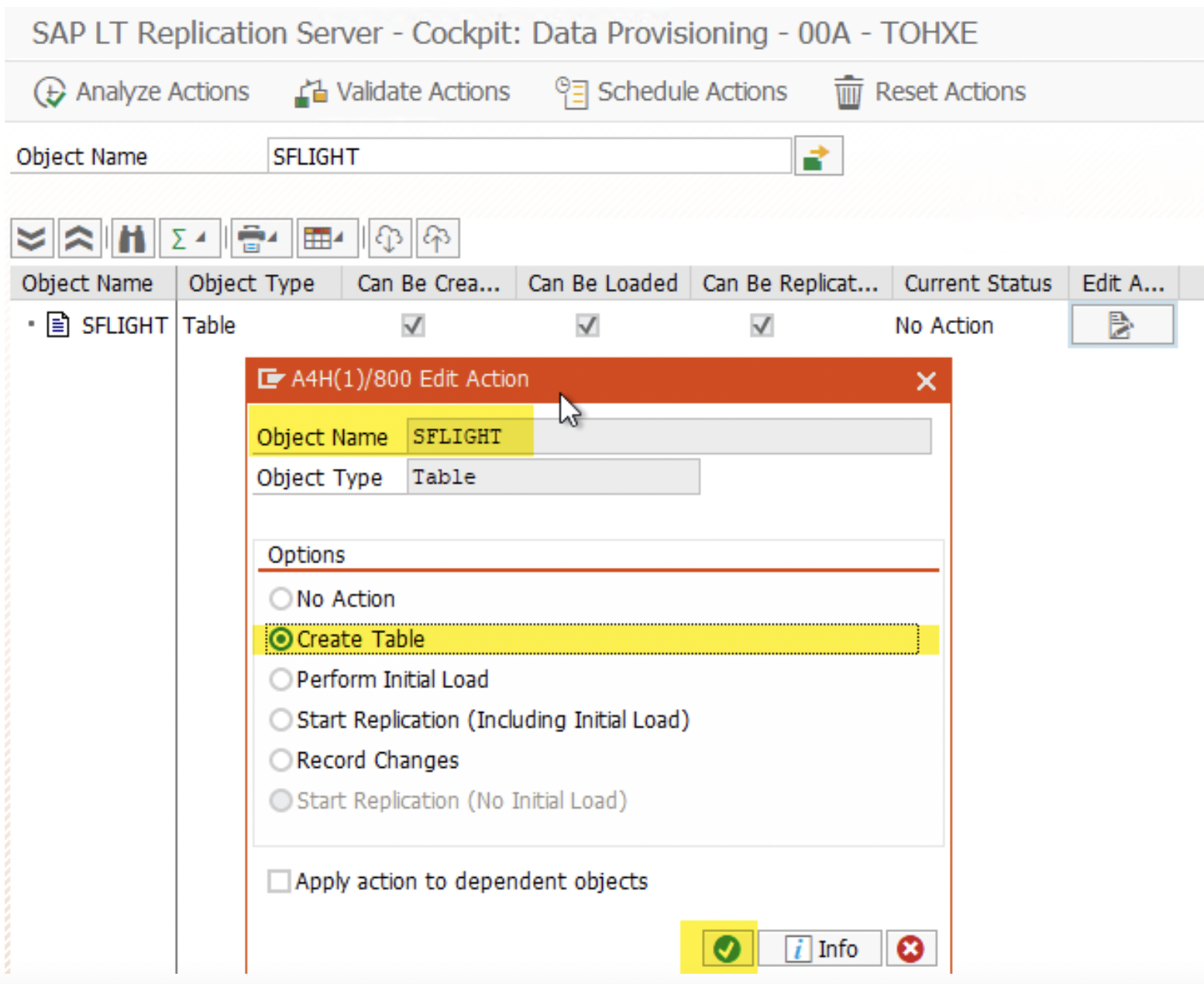
3. (Do this step for each table only once). Give the table name and choose the edit option. If this is the first MT_ID ( it can be any of 00A, 00B, 00C); first choose to create the table. This step will not be required in the subsequent MT_ID setup for data transfer.
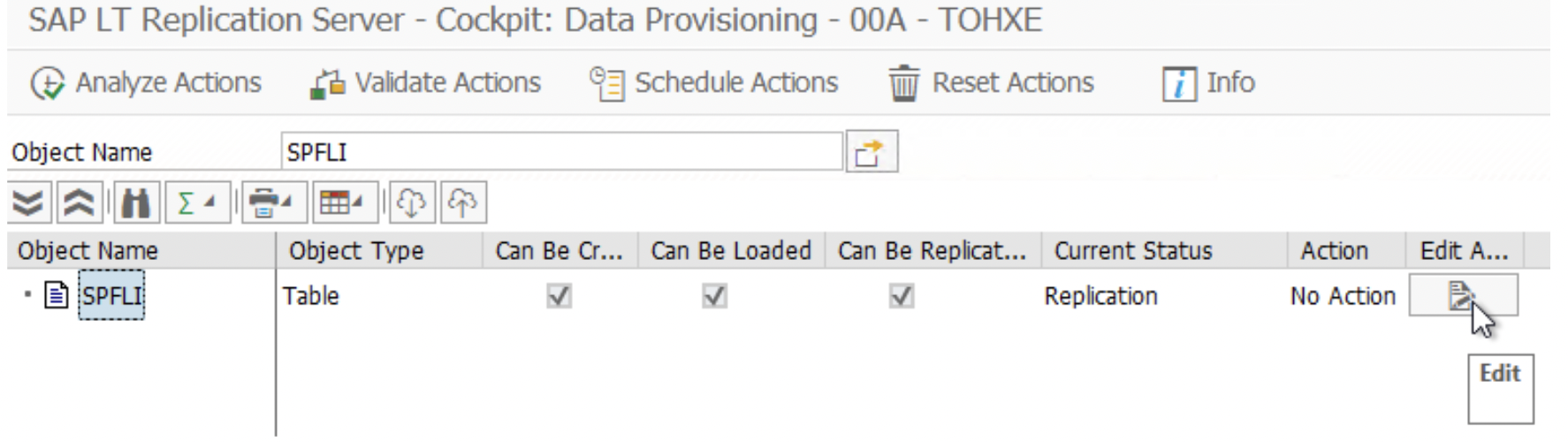
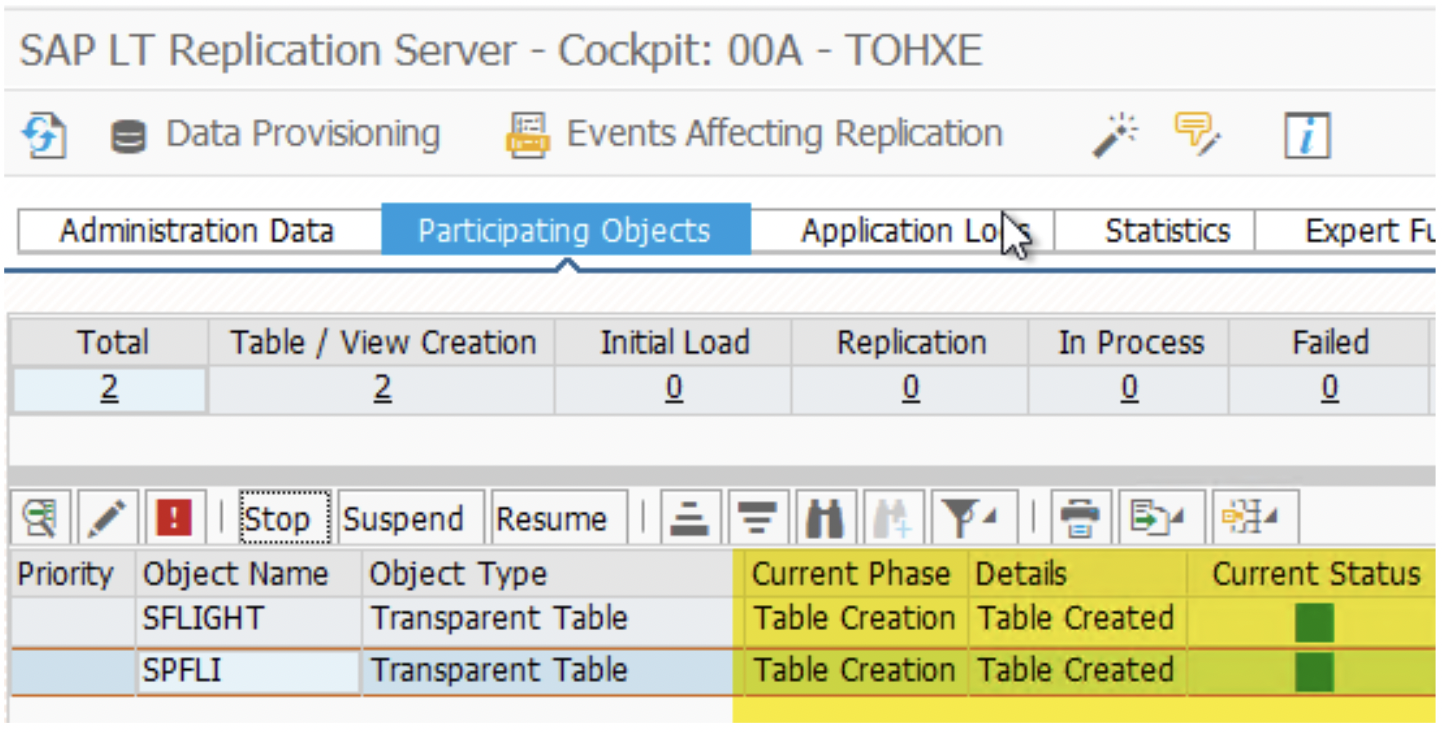
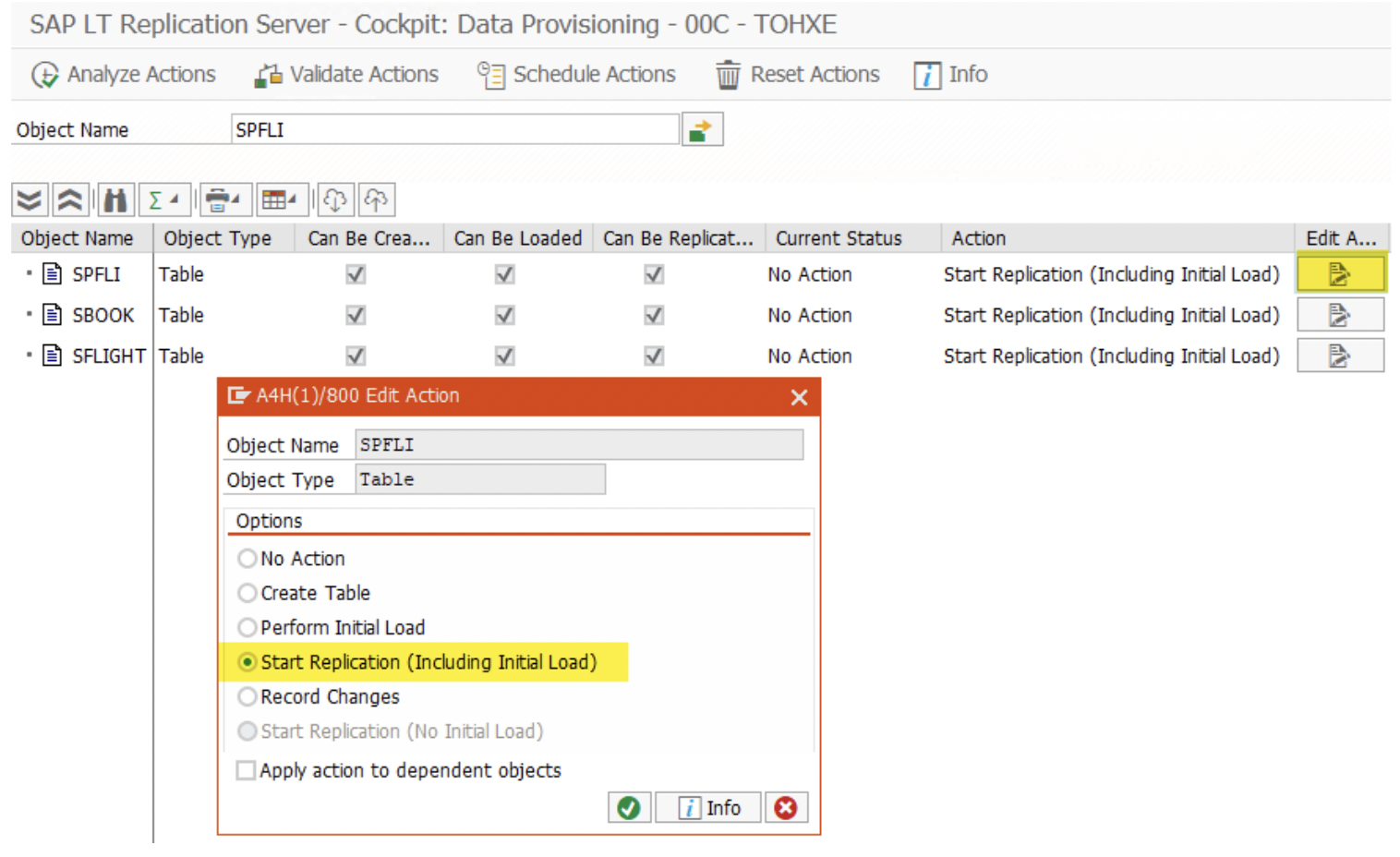
4. Once a table created successfully by current MT_ID/previous MT_ID, now start replication. This step is required for each MT_ID for replicating related source data.
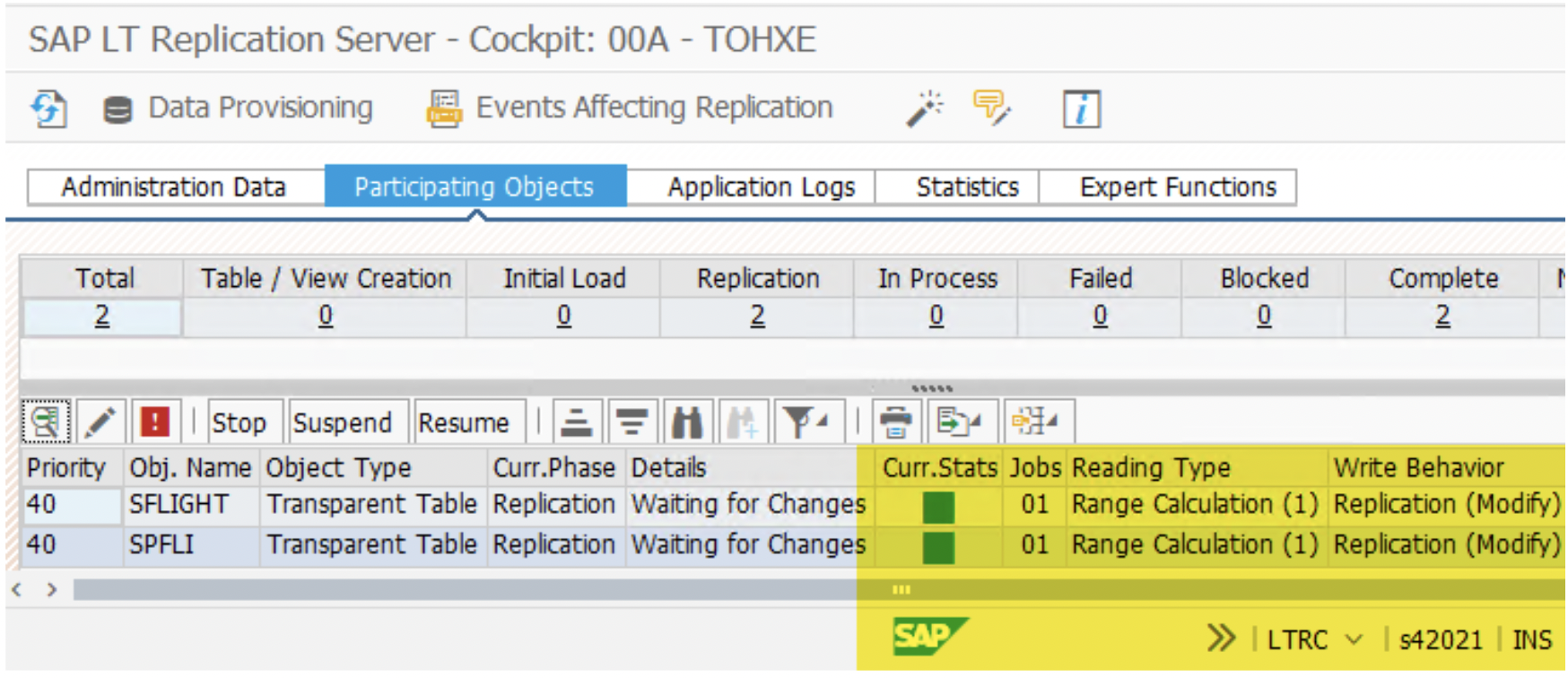
5. Once you complete the replication step, return to the LTRC transaction by pressing the back button and clicking on ‘Participating Objects’. It shall be in the stage of creating the related DB artifacts, i.e., triggers, logging table, and replication objects. Soon it will turn to green, showing that replication started successfully.
6. Repeat the above steps I-V( except step III ) for each MT_ID to replicate the attached source data to the target schema.
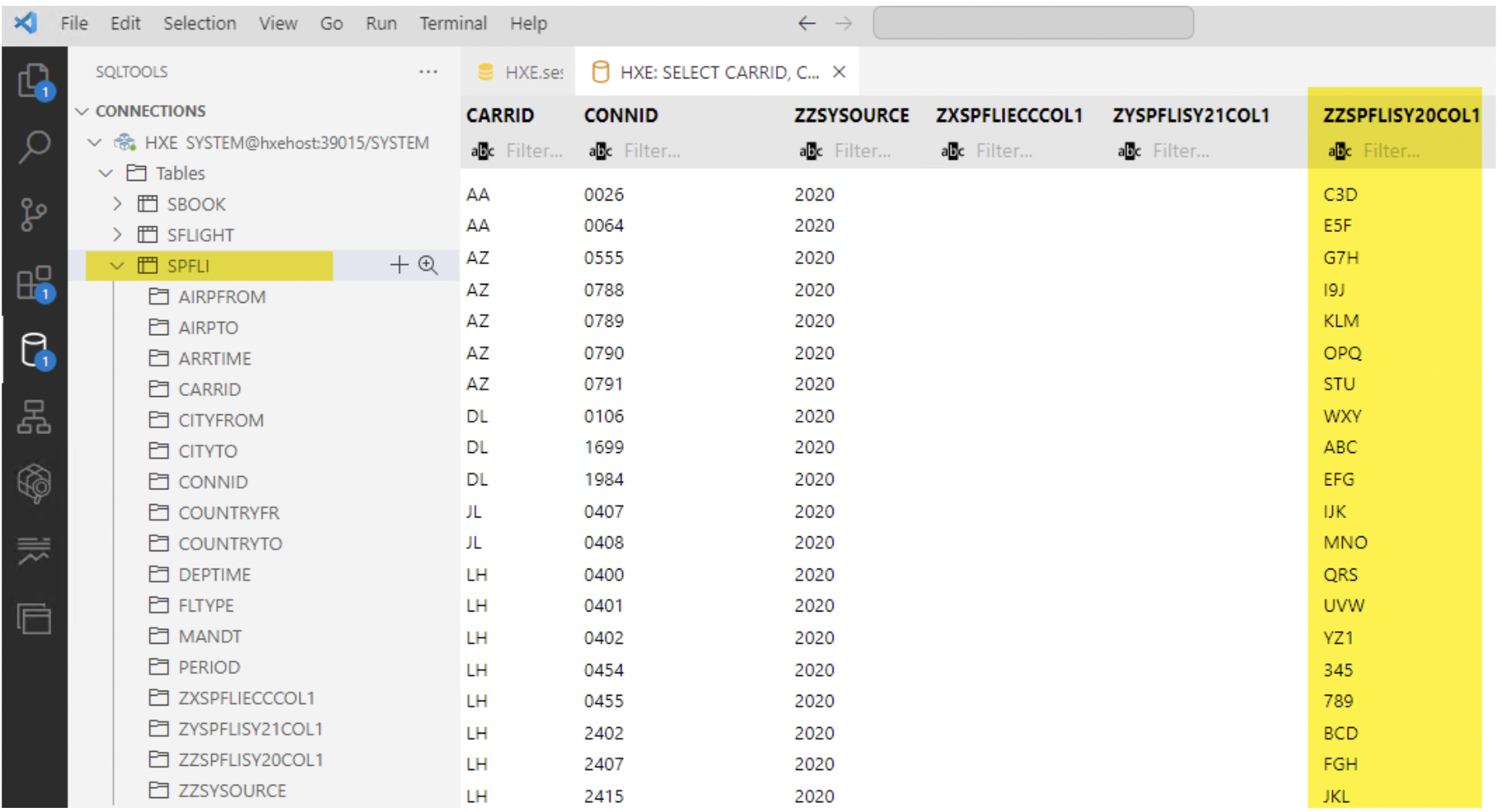
7. Once replication is successful, check the replicated data in the target system. We can see that SPFLI data is copied from all three sources.
S4HAN2020 source column ZZSPFLISY20COL1 data is replicated. However, the other 2 Z-Columns are unavailable in this source, so they remain blank. (MT_ID-00A).

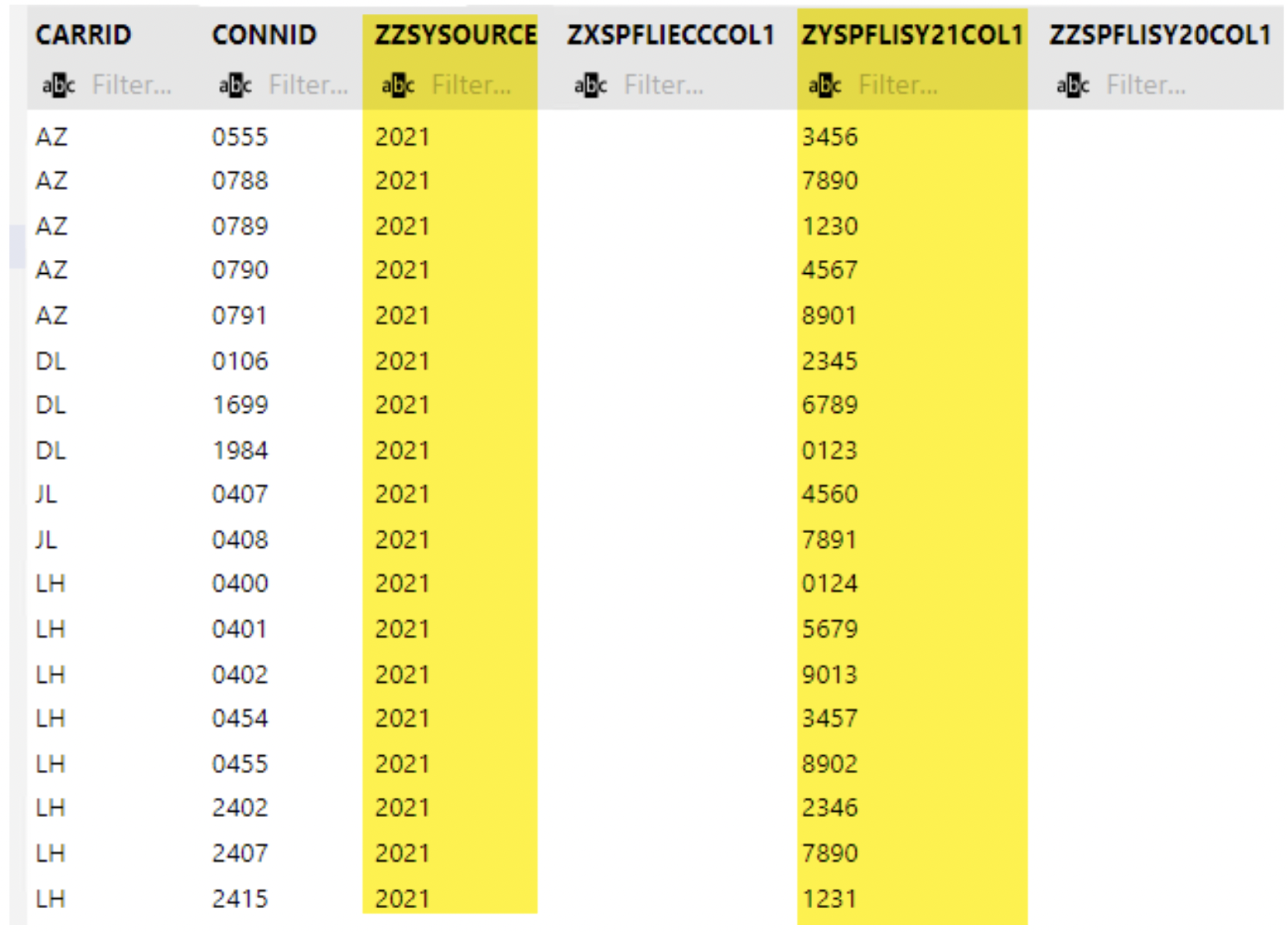
Similarly, for S42021( MT_ID-00B )

Additional SLT activities not covered in this blog-
Error Handling:
In case of any errors during the replication process, the SLT system provides error-handling capabilities. We can use the SLT data provisioning application to view the error log and take corrective actions, such as resuming the replication process or fixing the underlying data issues.
Performance Optimization:
To optimize the performance of the SLT replication process, we can use several techniques, such as partitioning tables, selecting the most efficient read methods, assigning multiple jobs for initial load/data replication, and tuning the database parameters. We can also use SLT configuration settings, such as the number of parallel processes, to optimize the replication process.
SLT vs. SDI:
Another popular method of data replication is HANA Smart Data Integration( SDI ). There are a few similarities and dissimilarity between SAP SLT (SAP Landscape Transformation) and SAP SDI (Smart Data Integration)-
Similarities:
- Real-time data replication: SAP SLT and SAP SDI enable real-time data replication from various source systems to target systems.
- SAP HANA integration: SLT and SDI seamlessly replicate data into SAP HANA for further processing and analytics
- Data transformation capabilities: SLT and SDI provide features for data transformation, including filtering, mapping, and aggregation, to ensure data quality and consistency.
- Change Data Capture (CDC): SLT and SDI use CDC technology to capture and replicate only the changed data, minimizing the impact on system performance.
- Heterogeneous system support: SLT and SDI support replication from heterogeneous source systems, including non-SAP databases and applications.
- Minimal impact on source systems: SLT and SDI minimize the impact on the performance of source systems during the replication process.
- Data replication monitoring: SLT and SDI provide monitoring and administration tools to track the progress of data replication, monitor system health, and troubleshoot issues.
- Transformation rules and mappings: SLT and SDI allow you to define rules and mappings to transform and manipulate data during replication.
- Schema mapping: SLT and SDI support mapping source system schemas to target system schemas, ensuring data consistency and compatibility.
- Integration with SAP tools: Both SLT and SDI can be integrated with other SAP tools and technologies, such as SAP Data Services and SAP BusinessObjects, to enhance data integration and analytics capabilities.
Differences:
- Purpose: SLT primarily focuses on real-time data replication within the SAP landscape, while SDI provides a broader range of data integration capabilities beyond SAP systems.
- Source system support: SLT is designed specifically for SAP source systems, such as SAP ERP and SAP CRM. SDI supports a broader range of source systems, including non-SAP databases and applications.
- Data integration capabilities: SDI offers additional data integration capabilities, such as data federation, data virtualization, and data services, which are unavailable in SLT.
- Connectivity options: SDI provides various connectivity options, including JDBC, ODBC, and web services, allowing integration with multiple source systems, whereas SLT has limited connectivity options.
- Data quality and enrichment: SDI includes features for data quality management, cleansing, and enrichment, which are not part of SLT.
- Transformation capabilities: SDI offers advanced transformation capabilities, including complex mappings, data aggregation, and data enrichment, which provide more flexibility in data integration compared to SLT.
- Replication latency: SLT offers near real-time replication with minimal latency, while SDI may have slightly higher latency depending on the source systems and replication configurations.
- Licensing model: SAP HANA includes SLT, while SDI is a separate product that requires licensing..
- Target system support: SLT is primarily used for replication into SAP HANA, while SDI supports replication into various target systems, including SAP HANA, other databases, and data lakes.
- Ecosystem integration: SLT is tightly integrated with the SAP ecosystem and leverages SAP technologies, whereas SDI offers more flexibility in integrating with third-party tools and technologies.
However, it’s important to note that the features and capabilities of SLT and SDI may evolve with new releases and updates from SAP. Refer to the official SAP documentation for the most up-to-date information on both products.
If you have an interest in viewing similar content, visit our blog, here.
View our LinkedIn, here.


