As an ABAP Developer, there are times when you might face a scenario where performance improvement is required when working on either existing reports or while developing a new one from scratch. With multiple techniques available to improve the performance of a report or any FM/Class Method for eg, Parallel Cursor plays a key role. Here’s why.
In ABAP, conventionally we use the LOOP statement using the ‘WHERE’ clause. When there are nested loops, the ‘WHERE’ clause would scan the entire table to find the matching key fields. The cost of finding the one key would remain the same for each row in the outer LOOP. The total processing time for scanning the inner table would add up quickly with more entries in the Outer LOOP.
In terms of performance, the cost is high and could become a key issue when working with some of the most commonly used standard tables like VBAK & VBAP, BKPF & BSEG etc. Sometimes this cost rises to a level where the program terminates with or without throwing a dump during execution. However, this depends on the requirements.
To overcome this bottleneck and reduce the performance cost, we use Parallel Cursor.
What is Parallel Cursor?
In Parallel Cursor, we first sort both inner and outer loop tables by the same key field and try to see if there is any entry in the second table inside the LOOP construct of the first table. We use READ .. WITH KEY .. BINARY SEARCH to check if an entry exists in the second table. Here we use the value of SY-TABIX record to LOOP on the second table using LOOP .. FROM index.. syntax.In simpler terms, we Read the Key of the inner table, Loop from that key when entry is found and exit the table when keys don’t match.
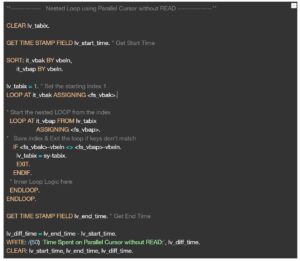
Below, is a sample code to demonstrate the time spent on a Normal Nested Loop vs Nested Loop using Parallel Cursor.
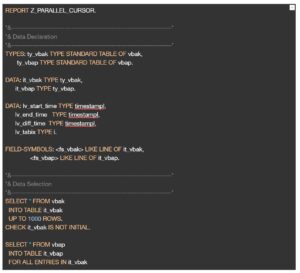
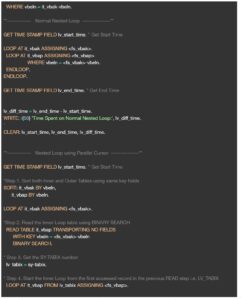
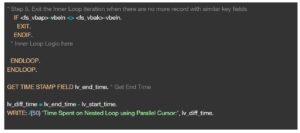
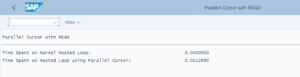
In the program result below you can see how Parallel Cursor performs when compared to normal nested Loops. The time taken by each method is displayed in microseconds. In the code sample we have restricted the select upto 1000 rows. However as the data volume increases, the performance difference is significant.
Caution: Don’t use SY-TABIX Directly
When you READ the inner table with the key, you get the index of the entry in the field SY-TABIX. You need this field to start the inner loop. However, SY-TABIX is set back to what it was before + 1 iteration. But the issue arises in debugging. Its value keeps changing and you won’t know what row you have started reading the inner table. Therefore, it would make more sense to use a Local variable to store the SY-TABIX value before looping through the Inner table.
Parallel Cursor without using READ Statement
This is a slightly modified version of the Parallel Cursor. To speed up the performance of Nested LOOP, we will exit the inner LOOP when both the keys don’t match, by saving the LOOP index in a variable. This index variable would be used in the LOOP construct to start the next iteration of the LOOP. Here, however, this index variable is set to value 1. This removes the dependency of the READ statement and consecutively boosts up the performance.
Attached below is a code sample which shows how we can use Parallel Cursor without using READ statement and compare the time with other methods mentioned above.
Below you can see how each Nested Loop method differs greatly in performance with each other.
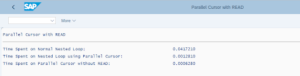
Conclusively, as per the data volume of the requirement, we have a variety of options to choose from for Nested Loop methods.
If you are interested in viewing similar articles, visit our blog, here.
View our LinkedIn, here.


