
With businesses expanding faster across different time zones, the long nighttime schedules for running jobs are getting increasingly shorter. Vast volumes of data, particularly some SAP programs executed in the background, may have run times of several hours and are scheduled preferably during non-business hours.
For custom programs that require substantial business data transfer from other SAP (or external) systems, the Remote Function Call (RFC) modules can be used. Suppose such program jobs have to be executed frequently and take a longer time for execution. In that case, there is scope for performance improvement with which we can reduce the job execution period.
When using normal (synchronous) RFC, the function module will be executed synchronously. Control will return to the calling program after finishing the execution. In case of time-consuming operations like queries to fetch massive data or loops to apply business logic in remote systems can take more time; there is a limit on the maximum time for dialog work process on the remote system side. Long-running jobs can fail with RFC timeout error. To avoid this and to execute the jobs within less time frame, we can utilize the parallel processing capabilities of the SAP system.
System Prerequisites:
Parallel processing was introduced in the SAP R/3 Release 3.1G (the Year 1998) onwards, so it can be used in all releases after that.
How it works:
Single and time-intensive tasks can be divided into multiple tasks that can be executed in parallel so that they can be finished in less time by utilizing available resources.
In SAP, work processes are assigned tasks (e.g. dialogs) to process. For parallel processing, we will need multiple work processes to process asynchronous RFC calls simultaneously. Unlike synchronous RFCs, asynchronous RFCs are called, and the calling program doesn’t wait for its completion; instead, it continues with the following code execution. This way, we can divide an enormous task into multiple smaller tasks to utilize free work processes, and multiple RFCs can be called in parallel.
Among all the work processes, we need to check the free work processes and should use some of them. Using the function module- ‘SPBT_INITIALIZE’ will get us the number of free work processes.
To execute function modules in parallel tasks, we need to add the keyword- ‘STARTING NEW TASK’ to the function call.
SAP has a built-in mechanism to avoid soaking up all the resources in the system by a parallel job and hence not affecting performance for other jobs or users. Additionally, we can optimize the sharing of resources with the help of RFC server groups, i.e. the set of SAP application servers that can be used to execute a particular program in parallel. By default, if we don’t specify any group, the default group(CALL FUNCTION STARTING NEW TASK with the addition DESTINATION IN GROUP DEFAULT) is selected, which includes all the servers that meet resource criteria. But we can also create more limited groups using transaction RZ12, as shown in the image below.

We can specify an RFC server group set using the keyword ‘IN GROUP’, which can put an upper bound on the number of work processes used in parallel programs. The image below shows the syntax for function call for parallel processing. In the parameter_list, we have to pass only the exporting parameters from the program to import the required parameters in the function module. To receive importing parameters in the calling program (parameters exported from the function module), importing parameters are captured in a separate subroutine/method, which we mention in the ‘CALLING/PERFORMING’ section.

Also, as these will be asynchronous FM calls, all the tasks may not be completed at the same time, so after completing all the calls, we need to wait until the execution of all the called FMs is completed to proceed with the following business logic in the calling program. The image below shows the ‘WAIT UNTIL’ syntax.

Different work processes will execute each thread of the function call. Once an FM execution is completed and the control returns to the calling program, the method/subroutine mentioned in the FM call (calling/ performing – at the end of the task) is executed to receive the FM results. We have to write code to receive importing parameters in this method, which can be achieved using the syntax shown in the image below.

An Example:
Consider a requirement to get all the actual cost documents data from the remote system for postings between 2 specific dates. Generally, COVP and BSEG table queries take time. To enhance the program performance, we can split the dates based on the number of free available work processes and call the remote FM in parallel tasks. The image below shows the parallel processing flow.
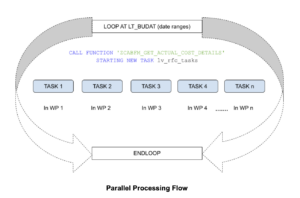
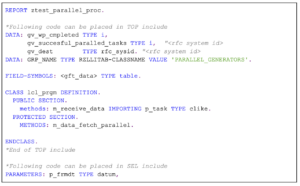
I’ve included below a sample code for using parallel processing.



The image below compares the time taken for a job to be a regular synchronous FM application and a parallel processing application.
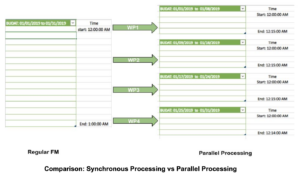
Now, suppose we need to fetch data for intervals of a month, 01/01/2019 to 01/31/2019; we have a total of 31 days (Including start and End dates); suppose we go for a regular synchronous Remote FM call. And, it takes around 1 hour to complete the execution of function module.
Same FM if we call asynchronous in parallel tasks, consider FM ‘SPBT_INITIALIZE’ finds eight free work processes; as per our logic, we use four among them by dividing the days into four ranges (3 sets of 8 days, and the last one of 7 days), each of the FM calls takes around 15 minutes. As all are triggered simultaneously, all the data fetch for the entire period is completed in about 15 minutes (same as one worker doing a task versus four workers doing the same task by dividing the workload). So if we calculate the percentage of a performance improvement, it will be improved by 75%.
With parallel processing capabilities, it is possible to boost the performance of longer-running jobs to a large extent. Suppose multiple long-running jobs are scheduled with proper planning (e.g. in a sequential manner). In that case, they can be completed quickly. This makes the required data updates available for users in different time zones during their respective business hours.
View our LinkedIn, here.


